I am currently working on a project that uses Smithy and Smithy4s extensively - and I want to improve my experience in Neovim, which is my primary editor.
Glossary
First of all, a couple introductions are in order.
Smithy
A language for defining protocol-agnostic interfaces with focus on later code generation. Developed and maintained by AWS, it's already used to define and generate AWS' own services and SDKs.
Smithy4s
A tooling package to transform Smithy service definitions into high performance HTTP server/client definition, backed by Cats Effect, Jsoniter, and Http4s.
It has many other goodies, but its main purpose is to cut down on boilerplate required for handcrafting HTTP routers, and instead treat service specification (written in Smithy) as a first class citizen, allowing the developer to focus on the business logic implementation, dealing mainly in high-level, domain-centric concepts defined by the service spec, instead of low level HTTP requests and codecs.
Smithy4s is under active development, but is already being used successfully to power high-traffic services.
Scala
You know it, I know it. You love it, I love it. Nobody will argue against the fact that it's the best (note that there's no comments in this blog, fight me on twitter instead you cowards).
NeoVim
It has Vim in the name, so you know it's powerful. It also has Neo in the name, so now you want to rewatch The Matrix.
More seriously though, Neovim is interesting to me because it bets on two things:
- LSP
- Tree sitter
To provide superior syntax highlighting (and source-level operations), along with developer experience close to what you would expect in a dedicated IDE.
(LSP) Language Server Protocol
This is a JSONRPC-based protocol for communication between the editor and a language-specific server, that provides things like completions/go-to-definition/etc. LSP implementation is built-in with Neovim, and you can see just how many different languages (or dialects, like Svelte framework or TailwindCSS) implement language servers of varying complexity.
Thankfully, there already is a Smithy LSP implementation which was largely maintained at DSS and donated/merged upstream to the AWS main line.
Tree Sitter
Not yet integrated into Neovim, but available as an officially maintained plugin.
It's both a parser generator tool and a library for very fast incremental parsing, with error recovery and speculative parsing.
Tree Sitter already includes a large number of very precise grammars for different languages (and some that are not as precise, Scala being one, unfortunately). It also comes with a special language (LISP-like, if you're into that) for defining highlighting queries, to achieve detailed highlighting with potential local scoping information. This is very different to regular expressions, used for highlighting in many modern editors.
Another important aspect is that TS grammars can be used by Github's main highlighting engine, Linguist (see grammar list and search for "tree-sitter").
Because of course - there's no highlighting for Smithy files on Github either! There are ways adding some highlighting (by making Smithy files impersonate Kotlin, in a twisted Face/Off-like abomination), but let's talk about it never.
Working with Smithy
In my project, Smithy specs do play the most central role, defining models, services, and even newtypes.
One important thing to note is that Smithy is a language, not a set of conventions defined using an existing language (like OpenAPI is defined in terms of YAML/JSON). This makes it attractive as it's designed from ground up only for the purpose of defining interfaces, instead of being a general purpose markup language (YAML).
Here we refer to Smithy as both the language and the associated Java implementation of it that provides useful functionality to load, verify, and manipulate models.
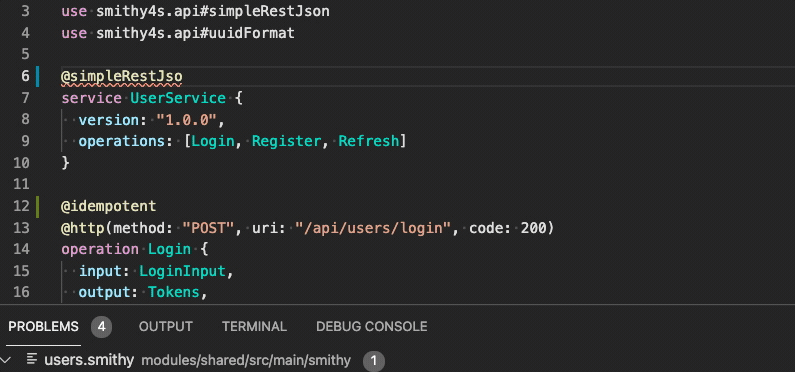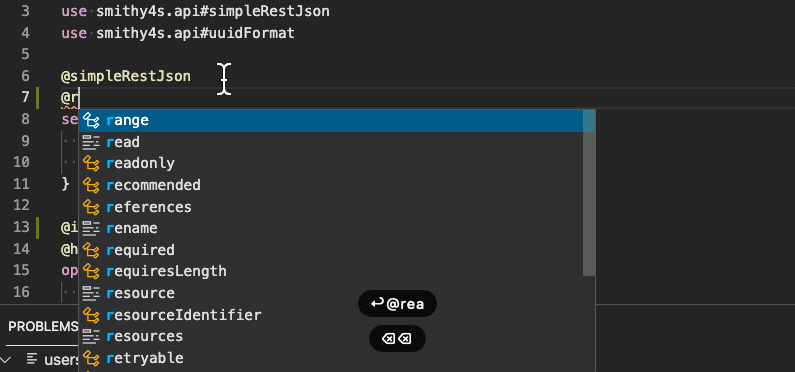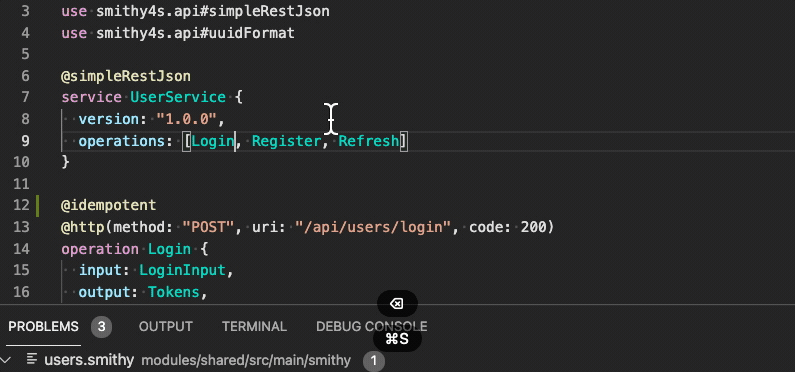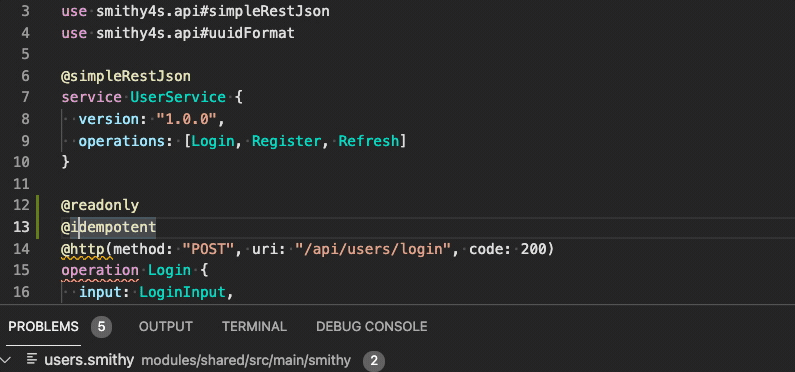
When loading models from files, smithy will verify the syntactic and semantic correctness of what's being loaded, but will also run high-level validators, such as "is a GET HTTP operation also annotated with @readonly". This validation mechanism is extensible and is pre-populated by a number of pragmatic defaults, some of which enforce API design consistency.
For example, if you mark a GET operation with @idempotent trait, you will get a warning:
This operation uses the
GETmethod in thehttptrait, but is marked with the idempotent trait
And an error if you mark it as @readonly as well:
Found conflicting traits on operation shape:
idempotentconflicts withreadonly,readonlyconflicts withidempotent
Having this rich set of errors and suggestions from the Smithy's model compiler is very useful, and can lead to a much better IDE experience.
On the other hand, Smithy being a separate language means that the tooling for it has to be created pretty much from scratch.
In IntelliJ IDEA
Currently, AWS are working on an IntelliJ plugin, that will use the Smithy language server.
I didn't have the opportunity to test it (nor do I have the need for it, as I haven't used Intellij in years). There's another, unofficial plugin, already published to the marketplace. I installed it, and it provides syntax highlighting and basic go to definition functionality, but doesn't seem to report anything other than syntax errors:
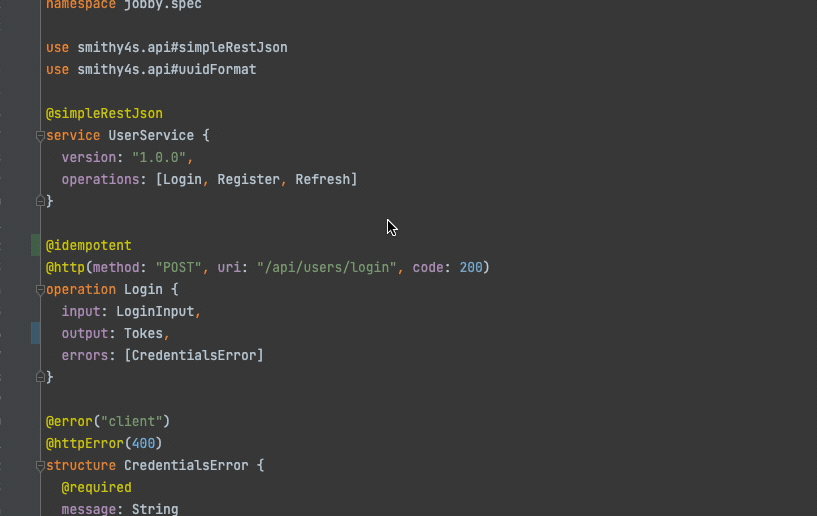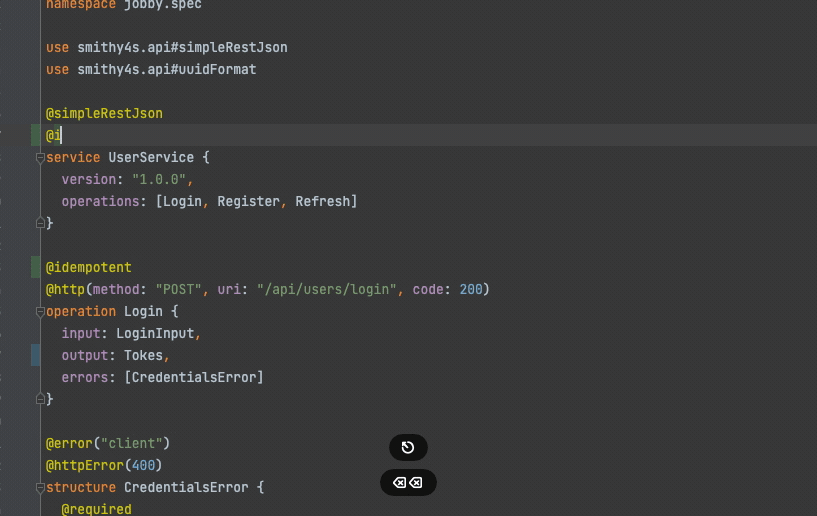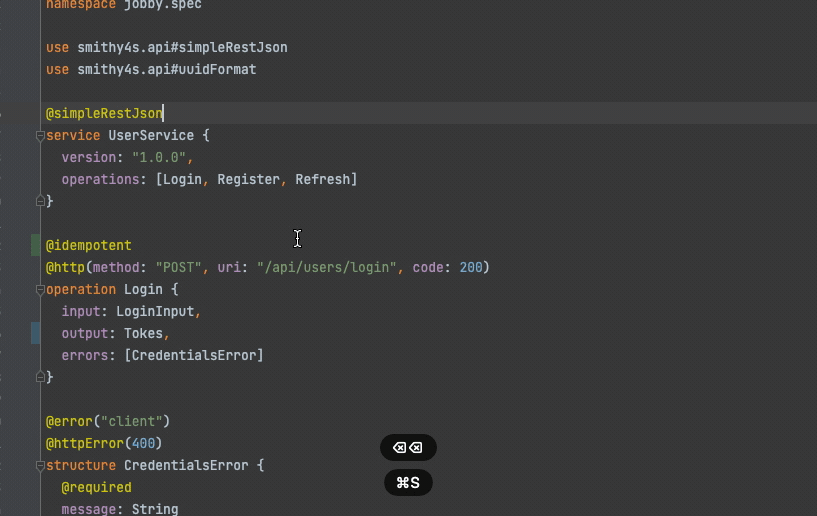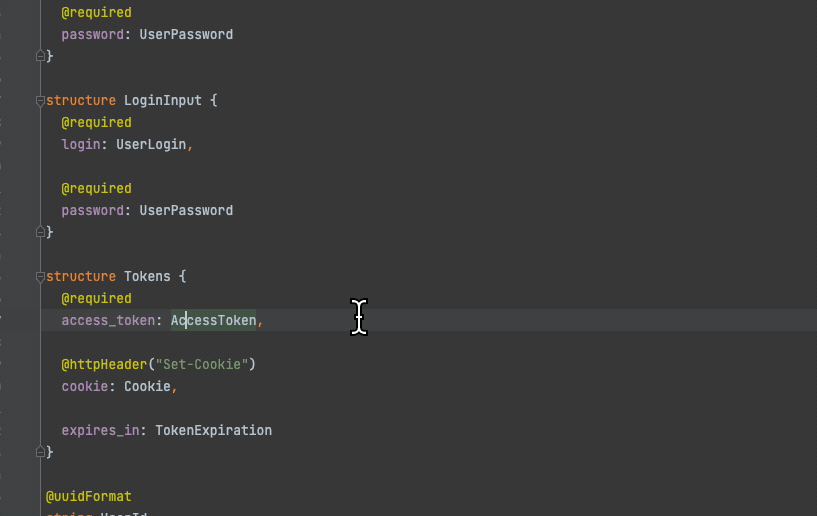
Overall, I think it's good enough to work efficiently with Smithy files.
In VS Code
Smithy4s started at Disney Streaming Services, where I worked on the tooling for it for some time under the watchful eye of its stern parent, my colleague and friend Olivier Melois (rebelliously twitterless, if you can believe it).
Over time, it was decided that IDE experience was paramount for the success of it, and as such VS Code was chosen as the target IDE - it has good LSP story, very decent extension debugging abilities and extension API in general, and it also seems to be crossing the treacherous boundaries between languages, loved by all the warring fractions of this little bubble we call Software Industry.
A VS Code extension was created, and inside of it a very simple regex-based grammar in TextMate format supported by VS Code. This syntax highlighting wasn't fantastic, but was enough to highlight (yikes) the general structure of the file.
Around the same time Language Server was created for Smithy (using Eclipse's lsp4j library), and bound to the extension by bundling Coursier as a small bootstrap script, only 120KB.
This in turn launches the language server when the extension is loaded and establishes a connection between the editor and the server. Coursier makes this entire process very simple, as long as the LSP is published to Maven Central.
To summarise, the experience of editing Smithy files in VS Code is excellent out of the box.
In Neovim
While VS Code is nice and works really well, I've been mostly enjoying NeoVim for my personal projects. And the experience with Smithy there is not as fluid.
Here are the main problems:
- By default, NeoVim doesn't even recognise
.smithyfiles. - There is not syntax highlighting to speak of
- No nifty extension to enable LSP for Smithy files
Let's breakdown these problems one by one.
Registering .smithy filetype
Both TreeSitter and LSP integration are triggered by opening a file with a filetype(see Neovim docs) that matches server/grammar configuration.
Luckily, there's a very simple way to tell Neovim to set the filetype to smithy whenever you
open a file that has a .smithy extension. Just drop this in init.lua:
vim.cmd([[au BufRead,BufNewFile *.smithy setfiletype smithy]])
Or if you are fancy like that, you can use the pure Lua version with the new autocmd APIs:
vim.api.nvim_create_autocmd({ "BufRead", "BufNewFile" }, {
pattern = { "*.smithy" },
callback = function() vim.cmd("setfiletype smithy") end
})
This is the first step in improving our experience.
Creating syntax grammar
If there is a simpler way - I don't want to know, judging by how much time I've already wasted on this.
To provide syntax highlighting for Smithy files, we will go at it using what I can only assume is the "blessed" way - creating a Tree Sitter parser grammar and providing highlighting rules.
The Getting Started experience for your first grammar is quite simple: generate a scaffold, start editing the grammar, test it with CLI.
The grammar itself is usually a single grammar.js file which uses Tree Sitter's DSL to build a grammar.
General process is to start from the top term (source_file) given to you by Tree Sitter and
gradually break it down, using the combinators provided by TS (such as choice, seq, repeat, optional, etc.) and glancing at Smithy's official grammar.
For example, here's the starting point of the grammar:
// ...
source_file: $ =>
seq(
$.preamble,
repeat($._definition)
),
_definition: $ => choice(
$.use_statement,
seq($.trait_statements, $.shape_statement),
$.shape_statement
),
preamble: $ => seq(
repeat($.metadata_statement),
$.namespace_statement
),
// ...
You can see we're using source_file (defined by Tree Sitter itself) as the entry point and define it as a sequence of
- 1
preamblegrammar rule expansion - any number of
_definitiongrammar rule expansions
And the definition of $._definition and $.preamble follow later. The grammar is by no means
great (I almost tanked this topic at Uni), but it works, somewhat.
This process is very much trial-and-error, and tree-sitter CLI doesn't have a watch mode, so to make
it a bit more interactive I've used fswatch and running a command like this:
fswatch grammar.js | xargs -n1 sh -c "tree-sitter parse test.smithy"
Which will output the AST like this:
(source_file [0, 0] - [19, 0]
(preamble [0, 0] - [0, 20]
(namespace_statement [0, 0] - [0, 20]
(namespace [0, 10] - [0, 20]
(identifier [0, 10] - [0, 15])
(identifier [0, 16] - [0, 20]))))
(use_statement [2, 0] - [2, 31]
(absolute_root_shape_id [2, 4] - [2, 31]
(namespace [2, 4] - [2, 16]
(identifier [2, 4] - [2, 12])
(identifier [2, 13] - [2, 16]))
(identifier [2, 17] - [2, 31])))
(use_statement [3, 0] - [3, 27]
...
and if the grammar failed to parse a particular node, you will see a ERROR node - meaning
you need to fix something!
So the process is
- Identify ERROR nodes"
- Fix the grammar
- Repeat until "good enough"
This process took some time but it's nothing compared to what languages like Scala require from grammars - Scala 3, for example, requires special lexer adjustments to insert special tokens for significant indentation - just like Python, or Haskell, or F#, or Ocaml.
You can see the "good enough" version of the grammar in my repository.
If the moon shines just right and you want to help me build the grammar, you can start by
looking at how number is defined in the grammar, and how it's actually defined in Smithy ABNF.
Now that we have the grammar ready in a repository somewhere, how do we make Neovim aware of it?
Well it turns out that it's actually simple. Let's re-open our init.lua which initialises Neovim config,
and add the following to it:
local parser_config = require "nvim-treesitter.parsers".get_parser_configs()
parser_config.smithy = {
install_info = {
url = "https://github.com/indoorvivants/tree-sitter-smithy",
files = {"src/parser.c"},
branch = "main",
generate_requires_npm = true,
requires_generate_from_grammar = true,
},
filetype = "smithy"
}
Because Tree Sitter grammars are distributed as NPM projects (all the configuration is generated for you by the tree-sitter CLI's bootstrap process), it can bootstrap itself from the repository without installing any extra dependencies (apart from NPM itself).
This way, if you run :TSInstall smithy, it will install the Smithy grammar.
If it all went well, you should be able to open a smithy file and be able to use a playground on it
by running :TSPlaygroundToggle:
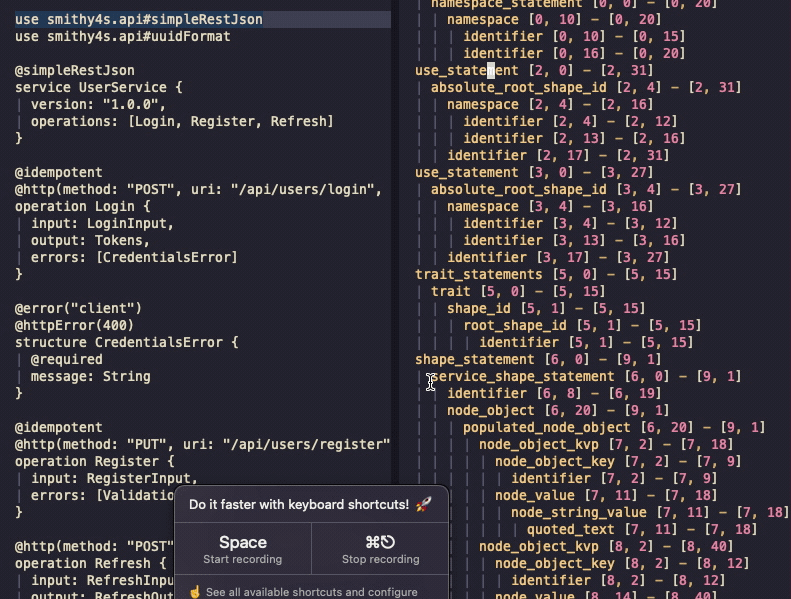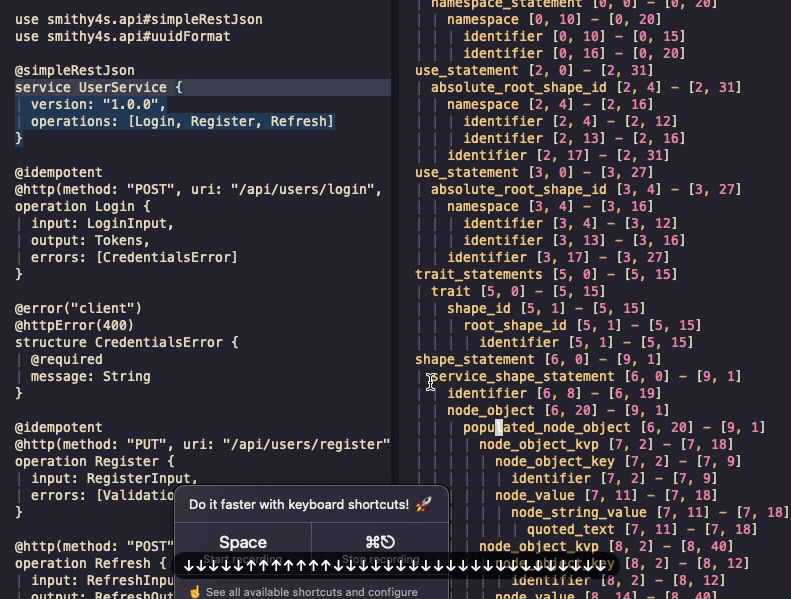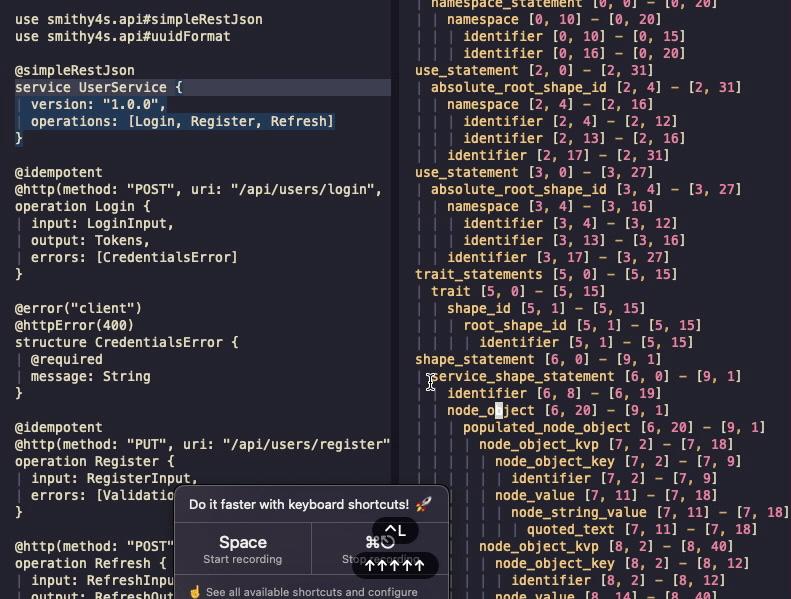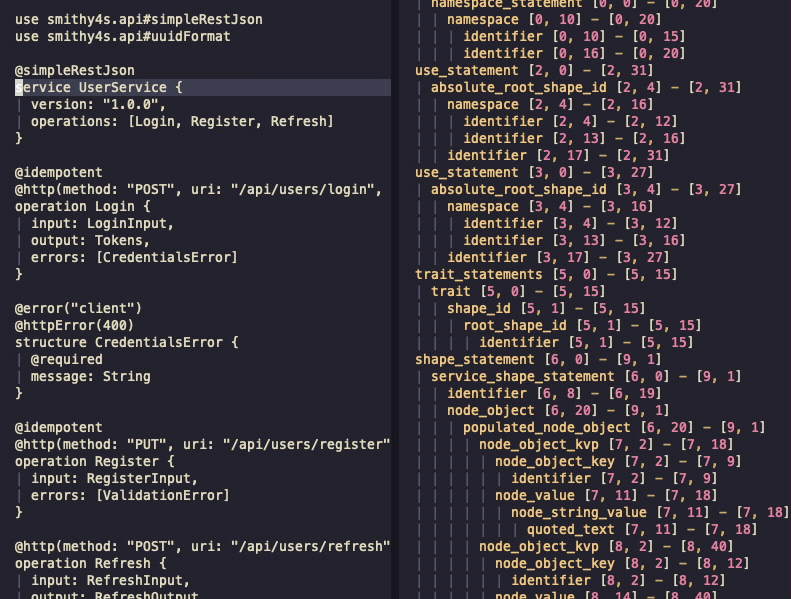
You can see the AST and can navigate between the source and the tree - it's just that there's no syntax highlighting. You can also see that I left the Gifox's banner in the gif - which was a mistake I won't correct because this was not supposed to be such a long post and I'm very tired.
How do we handle syntax highlighting then? Well the story is a little less glorious here.
You see, in the beginning it looks great - you use LISP-like syntax to mark the nodes in your AST as one of the built-in captures.
We'll put those rules into a queries/highlights.scm file. For example, the simplest rule
is marking some keywords to be interpreted as @keyword capture group, and "use" as @include capture group:
[
"namespace"
"service"
"structure"
"operation"
"list"
"map"
] @keyword
"use" @include
Some of the simpler grammar atoms can be mapped to built-in capture groups:
(number) @number
(quoted_text) @string
(comment) @comment
This is the general syntax - we're saying that number nodes from our grammar will be
mapped to @number capture group, known to nvim-treesitter.
We can go deeper:
(use_statement
(absolute_root_shape_id
(namespace) @namespace
(identifier) @type
))
You can see we're deconstructing the use_statement node, then further deconstruct
its child absolute_root_shape_id which consists of namespace (which we designate as @namespace capture group) and identifier (which we designate as a very generic @type capture group).
Why do this? So we can highlight the namespace and the imported identifier as different types of nodes:
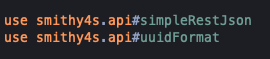
Another example of it is where we highlight identifier in a structure definition as a @type.definition:
(structure_shape_definition
(identifier) @type.definition
)
Because Smithy is quite regular and simple, we don't need many highlight rules to make it very presentable. Consider the difference:
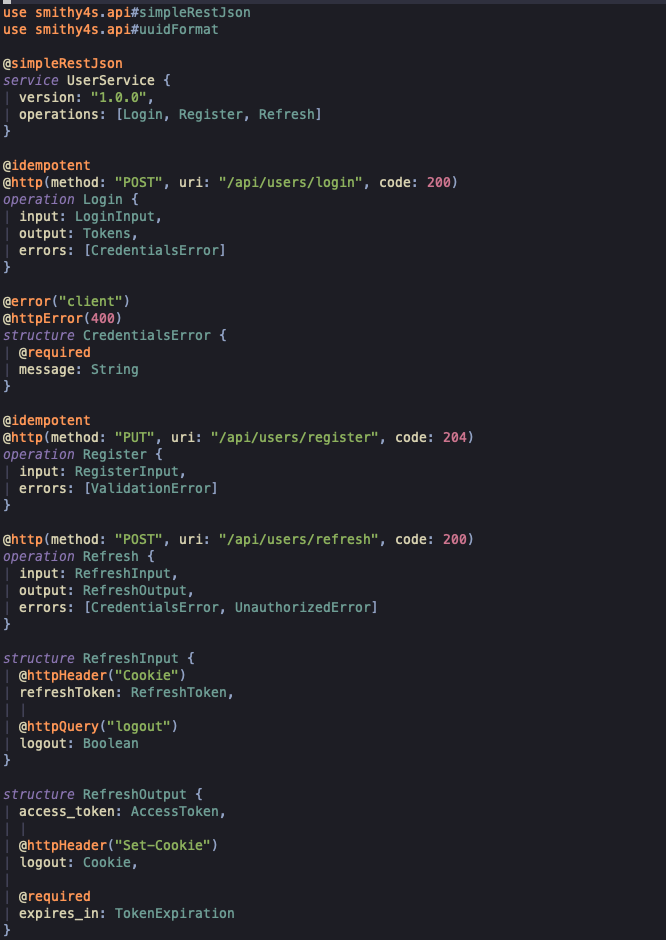
Now isn't this lap-slapping fantastic? So howeth doth one acquireth the sacred runes? Well it turns out that just having the queries in your repository doesn't matter:
Note that neither :TSInstall nor :TSInstallFromGrammar copy query files from the grammar repository. If you want your installed grammar to be useful, you must manually add query files to your local nvim-treesitter installation
(from nvim-treesitter docs)
I'm using Packer as my plugin manager, and I had to copy the highlights.scm file from the repo into
this location:
~/.local/share/nvim/site/pack/packer/start/nvim-treesitter/queries/smithy/highlights.scm
This was the biggest letdown of the entire experience, if I'm honest.
I do hope to one day have the time (and knowledge) to create a nvim-smithy plugin
that encompasses this grammar and installation of highlight queries.
Until that day comes, you'll have to copy the file manually, like a damn caveperson. Sorry.
The way I was developing the highlight queries was by using fswatch again, but this time
using tree-sitter CLI's highlight subcommand:
fswatch queries grammar.js | xargs -n1 sh -c "clear && tree-sitter highlight example-file.smithy"
Unfortunately, getting to this point wasn't easy. First, I would get no recognition of my .smithy
files by the Tree Sitter CLI.
It was suggested I run the configuration command:
$ tree-sitter init-config
Remove your existing config file first: <~>/Library/Application Support/tree-sitter/config.json
So it seemed I had to add my projects folder to the parser-directories array in the file above.
Additionally in the package.json of the grammar I had to add the following:
"tree-sitter": [
{
"scope": "source.smithy",
"file-types": [
"smithy"
]
}
]
Only after that could I verify that tree-sitter does indeed recognise my highlighting queries:
~> tree-sitter dump-languages
scope: source.smithy
parser: "/Users/.../projects/tree-sitter-smithy/"
highlights: None
file_types: ["smithy"]
content_regex: None
injection_regex: None
...
I've pieced all those configuration parameters and file locations from multiple places across documentation and user submitted issues. None of this was easy to debug and understand, and I would love to know why highlighting in particular is so hard to set up in comparison to parsing (which itself produces no visible artifacts in the editors).
At this point, I have enough to provide syntax highlighting for the Smithy specs I'm dealing with. It's by no means complete, but it's quite good for what I'm doing.
The hope is that it will eventually be added to nvim-treesitter's defaults, and to Github's linguist.
LSP
As mentioned before, the VS Code extension uses Coursier (words fail me when I try to explain how much I love this tool) to download and launch the language server.
Because I'm using Scala a lot (a lot) coursier is permanently available on my machine.
The simplest way of registering a custom LSP on my machine was suggested by the vimmer extraordinaire,
podcasteur du excellence, Chris Kipp: just drop a lua script in your
local installation of nvim-lspconfig, and hope that the plugin will pick it up like all the other
LSPs it's aware of. And by Merlin's hair, it worked!
The configuration looks like this:
smithy.lua
local util = require 'lspconfig.util'
return {
default_config = {
cmd = { 'cs', 'launch', 'com.disneystreaming.smithy:smithy-language-server:0.0.10', '--' , '0' },
filetypes = { 'smithy' },
root_dir = util.root_pattern('smithy-build.json'),
message_level = vim.lsp.protocol.MessageType.Log,
init_options = {
statusBarProvider = 'show-message',
isHttpEnabled = true,
compilerOptions = {
snippetAutoIndent = false,
},
},
},
docs = {
description = [[
Wake and bake, slumming it bruh
]],
default_config = {
root_dir = [[util.root_pattern("smithy-build.json")]],
},
},
}
(Note for future employers: yes, this commitment to documentation does translate to work environment)
The most imporant bit here is the line where we define cmd - this uses cs (coursier) to launch
the LSP server, and pass it argument 0, which would force it to interact via stdin/stdout streams,
not open a TCP socket connection on some port.
Another important bit is that we identify the root folder of our project by detecting smithy-build.json. This file is recognised by the LSP, and allows you to configure the build, for example import
smithy definitions from artifacts on Maven central or custom repositories. Users of Smithy4s typically
need to have at least this configuration:
smithy-build.json
{
"mavenDependencies": [
"com.disneystreaming.smithy4s:smithy4s-protocol_2.13:latest.stable"
]
}
To import things like @simpleRestJson and @uuidFormat.
And we need to drop this file into the following location:
~/.local/share/nvim/site/pack/packer/start/nvim-lspconfig/lua/lspconfig/server_configurations/smithy.lua
After you restart neovim, you should behold the wonders of full IDE-like experience in your editor!
Difficult questions
You may be asking yourself: "Anton, you have single-handedly upended the end to end experience of editing files in Neovim, while looking dastardly handsome, if I may add, is there even a point in asking what's next?". Sure, poppet.
Currently this experience is not portable.
-
Syntax highlighting must be copied to your local installation of nvim-treesitter, where it will no doubt go out of sync
I hope to polish the grammar, add tests to it, and make the grammar more minimalistic, and then try to contribute it upstream and make it official Smithy grammar.
This will allow me to copy the highlighting queries into nvim-treesitter itself.
-
LSP configuration must be initialised in your own local filesystem.
For people with self-restraint and one computer that's perfectly acceptable - but I have the habit of switching back and forth between linux and macos machines, where I must duplicate the configuration. Boo.
Perhaps a better way would be to follow in nvim-metals footpath and provide a separate
nvim-smithyplugin, which will configure everything when installed.Some day.
Admittedly, this is not a fantastic Getting Started experience, but we're talking about a super niche language in a super niche editor, so the fact that anything works is a modern day miracle.
NeoVim's bet on LSP seems to be paying off handsomely, as I haven't modified a single line of code in the LSP server itself, and I was able to get a ton of things working immediately.