TL;DR
-
We are using genetic algorithms to find an optimal Scalafmt config that minimises the amount of code changes in a given Scala source file
-
The work described is shipped in two parts: a generic library for genetic algorithms and a web application with Scala.js where you can optimise your very own config
-
Source code:
Scalafmt
Let's begin by very briefly introducing scalafmt as I try to explain why it's been on my mind so much as to throw genetic algorithms at it.
Scalafmt is a very powerful automatic code formatter for Scala 2 and 3, which is almost infinitely configurable. It is under the general umbrella of Scalameta projects and therefore powered by the Scalameta parser for the Scala syntax. This aspect means that Scalafmt often plays catch up with any new syntactical features that land in Scala 3, but generally it's been doing a great job at that.
It is available as a CLI, a JVM library, and a SBT plugin. The configuration for it is written in a file called .scalafmt.conf and uses HOCON format. When using it as a library, we can of course just pass the configuration using normal Scala case classes.
Configuration stability
One perfectly reasonable issue people have with Scalafmt is that same configuration can produce differently formatted files when you upgrade Scalafmt's version. As the project stabilised, the issue became much less pronounced, but you can still get the occasional annoying noise on a PR where a particular construct in your files is reformatted slightly differently in 3.8.3 than it did in 3.8.2.
In my mind, code formatting falls into the same category as maintaining build files – it's not something most developers actually want to do regularly. Those are the foundations upon which we build the actual products, so if your foundations require daily maintenance it becomes frustrating very quickly.
Not just whitespace
Another issue that comes up regularly is the fact that Scalafmt doesn't just do whitespace adjustment. There are formatters out there that do that for other languages (like gofmt) but they are also unhelpful and generally more trouble than they're worth (like gofmt, which doesn't even attempt to break up long lines).
Scalafmt adjusts line length, rewrites certain constructs according to dialect (e.g. _ into ? for wildcard type parameters), removes braces, introduces end markers, removes unnecessary parentheses, etc.
A lot of the more intrusive rewrites are hidden behind explicit configuration flags, which provides ample opportunity for developers to bikeshed, something that has to be nipped in the bud very early on by a decisive leader. No companies ever went under because of the technology choices, but many 1 failed because their engineers were to busy discussing code formatting.
Problem with existing codebases
A legitimate concern some Scala shops have is migration to Scalafmt from something like Scalastyle, Scalariform, or absence of automatic formatting altogether. This can often happen in places that started writing Scala early on and have accumulated a significant amount of code formatted, quite often, by nothing but IntelliJ default formatting rules. Those aren't verified in CI of course, so arguments about formatting are free-flowing on the PRs.
In this case it's reasonable to try and avoid the full codebase reformatting by adjusting the scalafmt config such that the result matches the current files. The match will never be 100% and is almost always much lower than that, but some disruption can be avoided. Main reason for doing so is trying to avoid something like git blame output from being polluted by the code formatting commits. Note that this argument has lost some of its spice when Git introduced the ability to skip certain revisions entirely from git blame.
Introduction to Genetic Algorithms (GA)
The subject of genetic algorithms (GA from here on) captivated me ever since it was introduced in my AI courses at university – this was the gentler time when pathfinding algorithms were part of AI curriculum, because all we wanted to do is watch 2D settlers go about their business looking for food or building barracks.
The main purpose of GA is searching for a solution, or optimising an existing solution, in a problem where we can clearly represent possible solutions in a form that allows a specific form of selection used by GA, and where the quality of each solution can be measured numerically and automatically.
I'm by no means an expert (not even a casual enjoyer) in GA, so the introduction here won't be exhaustive by any means, and will be factually correct only from a layman's point of view.
All of the generic code for this section is published in a library called Genovese which I don't really intent to maintain beyond the scope of this post, it was just easier to publish it to Maven Central to use in other projects.
Representation
To make the simplest variant of GA work, we first need to define the solution space and how it's represented in a form that allows for the mutation and selection procedures required by this family of algorithms.
Simplest representation we can have is a binary vector: [0, 1, 1, 0, 0, 1, ...]. Note that it's rare that we will have a problem which is naturally representable as such simple vectors – more often we have to define a translation from a rich problem space to a primitive binary vector space.
For example, if you are trying to solve a problem of lighting an office building on a shoestring budget, you want to figure out a configuration of light switches that produce enough luminosity across the floor area, while having the minimal number of lights turned on. Your solution representation is therefore a vector of [on/off, on/off, on/off, ...] for all the switches you have (in some stable order).
This problem remains simple if you have dimmable switches, as you can move on to floating point vectors: [0.5, 0.1, 0.0, ...] where each value represents the normalised (from 0.0 to 1.0) intensity of each switch. For the rest of the post this floating array representation is exactly what we will use, so let's define a type alias:
type Vec = IArray[Float]
Our GA process will be operating entirely on these vectors, and we will construct the actual problem solution only when presenting the results of the optimisation. In functional terms, if our solution space contains values of type T, then to make the GA optimisation possible, first two things we need are the following functions:
def materialise(vec: Vec): T
def encode(t: T): Vec
The vectors produced and consumed by these functions should be of fixed length, as the selection processes will rely on that. It is generally desirable that the mapping is a bijection – i.e. for any floating array we can produce a value of type T, and for any value of T we should produce a vector. Additionally, we expect the following to hold (roundtrip property):
forall[T]:
(x: T) => materialise(encode(x)) == x
Fitness
Through the process of mutation and selection our system will be producing vectors that represent various solutions to the problem – and GA will maintain and evolve a population of such solutions, aiming to gradually weed out less feasible solutions.
To do that, we need to define a fitness function that will evaluate each solution and produce a numeric value. For our system, let's assume that the function has to produce a floating point value from 0.0 to 1.0. In fact we use this range so much, let's codify it in a type:
opaque type NormalisedFloat <: Float = Float
object NormalisedFloat:
inline def apply(value: Float)(using
rc: RuntimeChecks = RuntimeChecks.Full
): NormalisedFloat =
runtimeChecks.floatBoundsCheck(0.0, value, 1.0)
value
inline def applyUnsafe(value: Float): NormalisedFloat =
value
inline def ZERO: NormalisedFloat = 0.0
inline def ONE: NormalisedFloat = 1.0
end NormalisedFloat
Note: RuntimeChecks is a very simple tool that allows disabling bounds check during training and completely inlining away the assertions
So the fitness function has this shape:
def fitness(x: T): NormalisedFloat
Where 0.0 means "terrible solution" and 1.0 will mean "excellent solution".
Often this function is very expensive to evaluate, so we would rather do it as infrequently as possible, and hopefully cache it somehow.
For clearer naming purposes, let's codify this particular function type:
opaque type Fitness[T] <: T => NormalisedFloat = T => NormalisedFloat
object Fitness:
inline def apply[T](f: T => NormalisedFloat): Fitness[T] = f
Population, selection, recombination, mutation
Here's a very simple view of what our particular flavour of GA is doing:
- Generate a population of possible solutions randomly
- Iterate for a fixed number of steps (generations) or until some condition is reached:
- Evaluate the current population using fitness function
- Use selection and recombination to increase the combined fitness of the entire population
- Use mutation to introduce new information into the population and avoid local minimum/maximum
Generating a population is easy, because it's just generating random vectors.
Evaluating the population can be quite resource intensive – but thankfully it's a trivially parallelisable problem.
The selection procedure can be implemented in various ways, but I chose the simplest one – just select some proportion of population with highest fitness. Let's say, top 80%. The remaining 20% are discarded.
To backfill the population to its stable state, we use the process of recombination to produce "offsprings" – new specimens produced by combining features of parents. In my experiments I used a very simple one-point crossover.
In a very unfun way this is basically eugenics. We are committing atrocities in the vector population.
And lastly, during the crossover procedure we introduce mutation – instead of a perfect recombination of parents into offsprings, there's a chance that a portion of an offspring will be randomly changed.
This mutation procedure is why it's important that our solution representation is robust – no value in a floating vector should be disallowed, and a valid solution should be constructed out of it.
Genetic Algorithms for Scalafmt configuration
With basics out of the way, let's see how we can apply GA to the task at hand – generating optimal Scalafmt configuration that produces least amount of changes in a given file.
Feature representation
In this entire project there were two things I've spent the most amount of time on:
- Deriving a vector representation for a scalafmt config, and
- Investigating a silly mistake which broke web sockets in the app
What made this part so complex? Well first of all, scalafmt config is not designed to be encoded as a floating vector array. Far from it – it uses various Scala types (integers, strings, booleans), along with a deeply nested hierarchy of case classes and enums.
To provide a suitable encoding for this type of data, we first define a slightly lower-level concept – a Feature.
enum Feature[T]:
case FloatRange(from: Float, to: Float) extends Feature[Float]
case IntRange(from: Int, to: Int) extends Feature[Int]
case NormalisedFloatRange extends Feature[NormalisedFloat]
case Bool extends Feature[Boolean]
case StringCategory(alts: List[String]) extends Feature[String]
case IntCategory(alts: List[Int]) extends Feature[Int]
case Optional(feature: Feature[T]) extends Feature[Option[T]]
Features allow us to reduce a complex task of "encoding a generic scala case class" to a two-step process:
- For a given product type (case class), produce a list of
Featureinstances - For each
Feature, define how it's encoded in a singleNormalisedFloatvalue without lost of information
Task #1 is quite a bit harder, so it will be covered in the Feature derivation section.
Let's start with the simpler task #2: on Feature[T] we want to define methods like this:
def toNormalisedFloat(value: this.type#T)(using
RuntimeChecks
): NormalisedFloat // 1
def fromNormalisedFloat(value: NormalisedFloat): this.type#T // 2
- That is, for a given
Feature[T]and a value ofTproduce aNormalisedFloat - For a given
Feature[T], and aNormalisedFloat, produce a value ofT
For some types of features it is trivial to define the conversions:
Boolis encoded in two disjoint segments – values above or equal0.5aretrue, and everything else isfalseNormalisedFloatRangeis identity – the value is unchangedOptionalis interesting as it wraps another (original) feature – we divide the space into two segments, where anything below0.5representsNone, and everything above it representsSome(...)and to produce the actual value ofTwe stretch the segment[0.5, 1.0]by normalising the given value:2 * (value - 0.5). This gives us a new stretch from0.0to1.0on which we can run the encoding/decoding methods of original feature.
Note that for Bool and Optional we divided the space almost equally between true/false, and Some/None. This means there's almost no bias towards any particular value, and if our random number generator is uniformly distributed, we should see the values pop up with equal frequency.
The various range and category features all work in a similar way – if we can divide the [0.0, 1.0] range in equal segments that correspond to those values, we can provide a lossless encoding. For more details, check out the actual code.
Feature derivation
Now for the hard part – for a given case class, how do we define a process that encodes it into a floating vector?
Before we begin you might ask yourself – why do we even need this? What is the problem in working just with arrays of Feature[T]? Even outside of the motivation for this post, adjusting scalafmt configuration which is, in fact, a case class, it's not difficult to imagine that it's far more likely to find a Config case class being used to drive business logic in an application than to find a list of nameless features lying around.
As it's the case classes that often feed into the business logic, I felt it was important to provide a mechanism to produce values of those case classes directly, instead of leaving the conversion logic to the user. Well, "directly" does a lot of work in this sentence – after all we need to bring the case classes down to the level at which our GA framework operates, and then back up, which will involve all of the conversion logic, we just try to generate as much of it as possible at compile time.
After thinking for a whole of 2 minutes about this, I decided to start with a typeclass approach, defining Featureful[T] as the type class which contains the logic for how a given type T is encoded into a vector of floats:
trait Featureful[T]:
def features: IArray[Feature[?]]
def toFeatures(value: T)(using RuntimeChecks): IArray[NormalisedFloat]
def fromFeatures(fv: IArray[NormalisedFloat]): T
We assume that one of the laws of Featureful is that features and toFeatures produce arrays of equal length.
Exercise: what would the definition of class Features(values: Feature[?]*) extends Featureful[IArray[Feature[?]]] look like?
There are some other cases for which it's trivial to define instances – for example a tuple of Feature[?] values.
But for some random case class we need to write a derivation mechanism. Scala 3 documentation has a detailed specification and document on using macros for derivation which is what I based my own implementation on.
This derivation mechanism allows writing things like
case class Breaks(x: Boolean, y: Boolean) derives Featureful
case class Cfg(test: Boolean, breaks: Breaks, z: Option[Boolean]) derives Featureful
And an instance of Featureful[Cfg] is derived for you – add a Fitness[Cfg] written by hand and you can invoke the GA training algorithm! Nothing else is required.
In this case the vectors produces by Featureful will be 5 elements long – the Breaks case class is getting spliced into the Cfg's vector.
Notice how I strategically used Boolean in the parameters – that's because encoding booleans requires no additional information – there's only two values, which are encoded in static segments on a number line.
In a similar vein, encoding true enums (with no fields, just values) is simple:
sealed abstract class Oneline derives Featureful
object Oneline:
case object keep extends Oneline
case object fold extends Oneline
case object unfold extends Oneline
enum Wrap derives Featureful:
case no, standalone, trailing
They get translated to a Feature.StringCategory because all the necessary information is available at compile time.
What if one of the fields is just Int? Or Float? Or String? That's where derivation will require a lot more information from the user. To that end, we can just add a derivation method that takes a special field config:
case class Config(
test: Boolean,
h: Float,
x: Int,
z: Float,
d: NormalisedFloat,
r: String,
f: Oneline,
t: Option[Boolean] = None,
t2: Option[String] = None
)
given Featureful[Config] =
derive[Config](
FieldConfig(
Map(
"h" -> Feature.FloatRange(1, 25),
"x" -> Feature.IntRange(500, 1500),
"z" -> Feature.FloatRange(300f, 600f),
"r" -> Feature.StringCategory(List("a", "b")),
"t2" -> Feature.StringCategory(List("hello", "world"))
)
)
)
The values in this config must be statically known to the compiler, and this way we can verify whether all fields are present, and the names are correct, and that types align.
Most importantly, this allows us to provide Featureful instances for classes that come from outside of our control, such as ScalafmtConfig! For example, here's me providing some information to derive a Featureful[BinPack] and Featureful[Docstrings] which are nested somewhere in the wider config:
given Featureful[Docstrings] = Featureful.derive[Docstrings](
FieldConfig(Map("wrapMaxColumn" -> Feature.IntRange(0, 1)))
)
given Featureful[BinPack] = Featureful.derive[BinPack](
FieldConfig(
Map(
"literalsMinArgCount" -> Feature.IntRange(1, 8),
"literalsInclude" -> Feature.StringCategory(List(".*")),
"literalsExclude" -> Feature.StringCategory(List("String", "Term.Name"))
)
)
)
Doing this for an entire config is quite tedious, so I gave up pretty early and instead defined a ScalafmtConfigSubset with fields I'm interested in:
case class DialectOptions(dialectName: String)
given Featureful[DialectOptions] = Featureful.derive(
FieldConfig(
Map(
"dialectName" -> Feature.StringCategory(List("scala213", "scala3"))
)
)
)
type ScalafmtConfigSubset =
(Docstrings, Comments, Indents, BinPack, OptIn, DialectOptions)
given Featureful[ScalafmtConfigSubset] =
Featureful.deriveTuple[ScalafmtConfigSubset]
And this is what we will be optimising going forward.
Note that there are certain features that I'm yet unclear how to encode – lists of variable length, seemingly arbitrary strings, enums which contain cases with fields, etc. Genovese will need to be extended to at least allow ignoring those fields entirely and delegating to some known default.
Defining fitness function
We're tantalisingly close to getting this working! To define a fitness function, we need to go back to our original objective – producing a config which leads to minimal number of changes in a particular file.
Producing the formatted file for a given config is very easy - Scalafmt exposes a Scalafmt.format(text, style = config) method. Note this operation can fail – i.e. if there are parsing errors. If it fails, we immediately give this config a 0.0 score – mainly to punish configurations with incorrect dialect (i.e. trying to format modern Scala 3 code with Scala 2.12 config).
I really wanted to avoid writing any string diffing myself, so it made me happy to find a library that does it. It's only published for Scala 2.13, but we can use it from Scala 3 without any issues.
Therefore our fitness function is defined as
- Format file contents with a given config
- Punish failed formatting with zero score
- Use NeedlemanWunsch's scoring algorithm to compare it to original text
- Normalise the score into the
[0.0, 1.0]range
Thanos cache
What I noticed very early on is that the whole process turned out to be quite heavy on the olde CPU.
As we need to evaluate all the specimen in the population over the course of multiple generations, the overhead of scalafmt parsing and formatting adds up quickly, and grows quite a bit with file size.
To help with that, I made an assumption that over the course of training, some configurations will stabilise and will be rarely removed because they are consistently the best in the population. And given the fitness function is fully deterministic, we don't need to always re-evaluate the same configuration.
Therefore, we can keep around a limited cache of values and the fitness assigned to them. This should speed things up quite a bit, at the expense of memory.
But what do we do if cache is full? Retaining old records might not be beneficial because if the training process has moved on into a more productive direction, the cache will contain older, inferior configs.
To fix this issue, we randomly remove 25% of the cache everytime we reach capacity. This will happen quite frequently of course, but the hope is that the rate of cache hits will increase as time goes by, and the capacity will not decrease as fast.
At this point we have all the nuts and bolts required to get this rusty bucket on the road. I even added an actual test running some training for parts of the scalafmt config. But to make it more presentable I decided to do what I do best: waste a lot of time deploying a barebones web app somewhere just so I can say I did.
Web app
To present this work, I've developed a small web application with a Scala JVM backend, Scala.js frontend, all packaged as a Docker container and deployed to Fly.io.
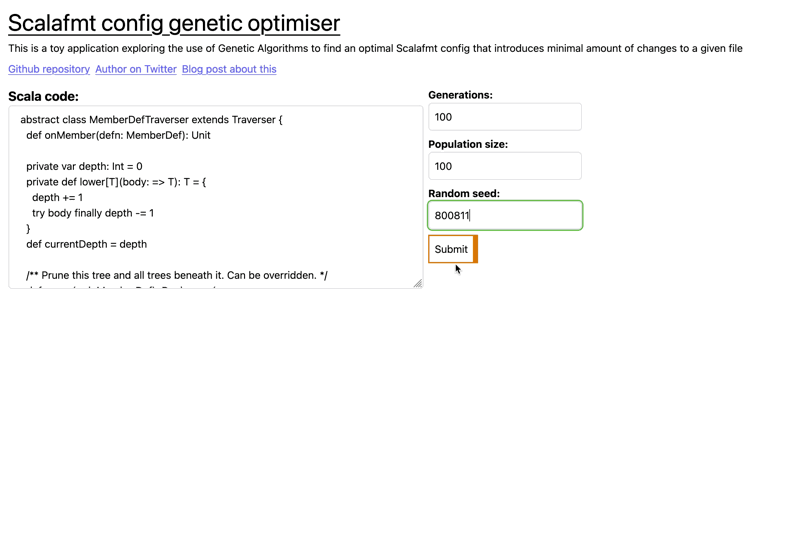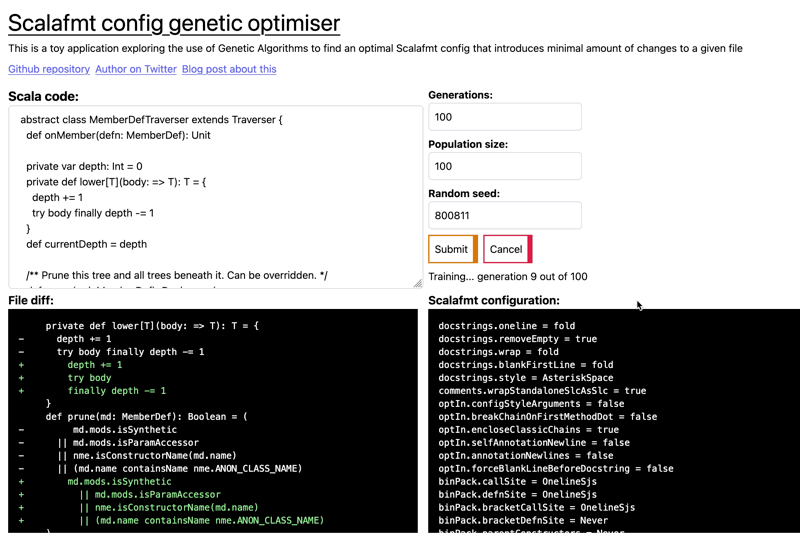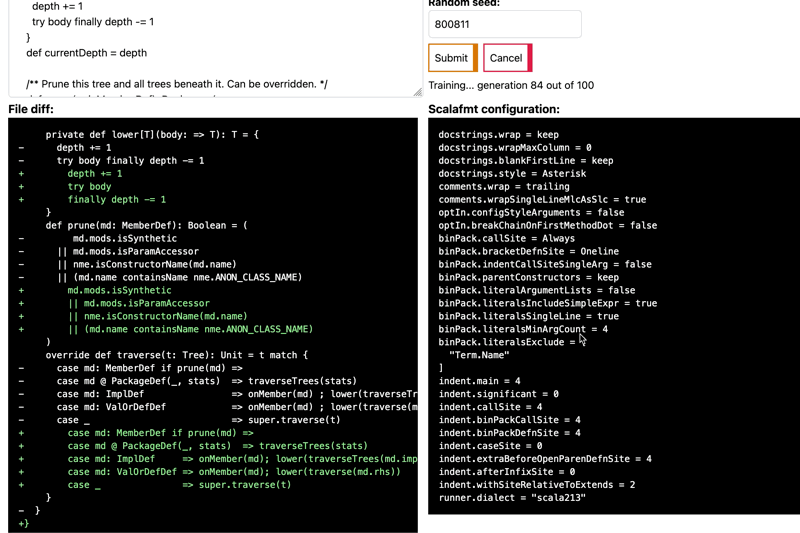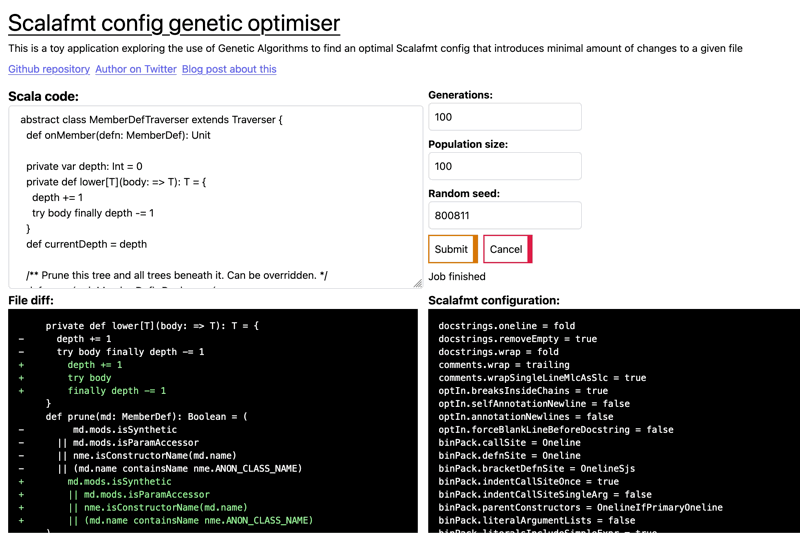
I won't go into any of the actual code, instead attempting to describe the work I've done in a way that will entice you to actually read the code and possibly learn something.
Backend with Cask
I've been writing a lot of code recently that can only be defined as imperatively-functional – as opposed to purely-functional code which constitutes the vast majority of code I worked on at, for example, Disney+.
To continue in that vein, I decided to go with Cask and uPickle as main libraries for the webapp. The functionality is not very difficult:
- Supporting a Create and Halt operations for training jobs – with some very basic validation of the parameters to ensure my free Fly.io instance doesn't blow up
- Running various clean up operations on a schedule, say every second, for jobs that have not been checked on by the submitting user in too long a time
- Support a websocket connection for client to receive updates about the training process, and for it to send ping messages to ensure the server only trains the jobs that are being observed by users
My overall impression of writing this webapp was quite pleasant, with websocket endpoint proving most challenging, just as expected. I found that Cask delivers on its promise of simplicity, while providing some minimal niceties (like implicit conversions to responses provided for uPickle's JSON values) that make the code more concise.
Things were going well until I deployed the app to Fly.io – that's when I immediately noticed an issue with websockets. The messages weren't being sent every second, but rather were buffered and sent out all at once once training finished.
This problem bothered me for days, as I wanted to be done with this project already, and yet I couldn't show it in the state that it was. Running it locally of course was perfectly fine.
My working theory is that this is related to the nature of the CPU-intensive training process and the extremely limited resources available on Fly.io's shared-cpu-1x instances – this leads to thread starvation of the Cask's actor that is responsible for sending out the messages.
In parallel to solving this particular problem (by tweaking parameters, and jumping off of the execution context that Cask uses internally), I started to wonder what would a backend look like if it was written with Http4s – my library of choice when it comes to writing anything I'd consider to be serious and/or involving some usage of concurrency and resource management.
Backend with Http4s
Originally I wanted to provide a version of the backend with http4s only for side-by-side comparison.
To keep the comparison fair, I opted to use the same JSON library in both backends, and inlined most of the code instead of extracting it into the helpers – this allowed me to write the backend in a more natural way for each of the libraries. Note that I make no claims about the fairness of the comparison – it was never the goal.
In the end the implementations are comparable in readability, with the caveat that http4s/cats-effect implementation readability is impeded by one of its overarching principles – explicitness about resource management and concurrency.
The added benefit of this implementation is that I was able to achieve much better fairness in terms of CPU utilisation, and was able to run several jobs concurrently while still receiving websocket updates in separate browser windows. This is not surprising as the runtime is optimised for fairness, which makes total sense for this sort of multi-tenant web app I'm building (wouldn't want a single training job to stall the entire instance!)
With all that said, http4s implementation is the one I use on the live demo instance, as it's the only one I managed to get working reliably on the tiny instance I have.
Frontend with Laminar
I decided to go for what's becoming my frontend stack of choice, which I will call VELTS - Vite, Scala.js, Laminar, TailwindCSS, where E stands for "Excellence".
Not much to say about it – hardest part was websockets again, and I decided to try out the Laminext extension library for that.
Deployment
For deployment I chose Fly.io as my cloud provider and a self-contained Dockerfile as the packaging solution. Both of these served me reasonably well in the past for deploying hobby projects.
The project is built entirely inside the container and I took great care in the Dockerfile to ensure as much as possible gets cached to speed up the build time.
The packaging can be improved still if the frontend is no longer served from the backend, but rather by something like NGINX. I have an example of that in one of my templates.
Conclusion
In this post we have briefly introduced Genetic Algorithms and applied a variation of them to a problem of discovering the optimal Scalafmt configuration.
To demonstrate this functionality, a webapp was built with Scala and Scala.js, and not one but two versions of the backend are provided for comparison: Cask and Http4s.
I hope you enjoyed this post, if you have any questions or comments, please reach out on Twitter or through Github Discussions.
Appendix A: Rant
Note: if you use and enjoy automatic code formatting, you can skip this section entirely
Note: this section was originally at the beginning of the blogpost, but I quickly realised that putting it there will make this post more about my negative feelings towards some trends in the industry, rather than what it's really about – yet another silly project I committed to while abandoning the projects that could realistically bring me money
If future historians were to excavate the remnants of internet of old (the internet of now as we currently know it), they would be surprised at the significant amount of space in it wasted by arguments about automatic code formatters.
This is not one of those issues where I'm perfectly content in sitting on the fence – if you work on a project with other people, you should be using automatic code formatters. If you are in a leadership position, you should also put a hard moratorium on any arguments about formatter configuration changes. You see, unless code formatting is mandatory and made to be unavoidable and its configuration unapproachable, software engineers of all levels will naturally settle in a state where it's all arguments and no work.
It's very easy to argue about immeasurable things, and our brains happily waste the excess calories on those arguments, rather than doing any work that is even marginally harder than yapping. Remember that tabs-vs-spaces is still something people argue about – very serious people with very serious jobs bitch about it on the Internet.
In my personal experience, code readability was always a function of three parameters: code organisation, naming, and syntax regularity. Formatters such as Scalafmt only help with syntax regularity, the rest is much harder to fix, and is almost entirely up to the programmer.
Additionally, formatters should actually format the files, instead of merely shouting at you about misaligned whitespace. Manual whitespace adjustment is a waste of time, and I cannot seriously consider arguments that manual code formatting is part of the "craft".
If you disagree with my opinions on this, please feel free to add your concerns in the comment section below this post.
-
according to statistics I just invented
↩