TL;DR
- Building a MacOS app using Swift, delegating some logic to Scala Native
- Github repository
- Tweet where you can add respectful comments and ask questions
Introduction
A while back I read a blog post by Mitchell Hashimoto, "Integrating Zig and SwiftUI" (post, tweet) which immediately piqued my interest. So much so that I immediately went ahead and did something similar with Scala Native (tweet).
Ever since I wanted to expand on this experiment and really go the whole way, implementing a non trivial application. A few weeks ago I decided that implementing a desktop app for Twotm8 (github).
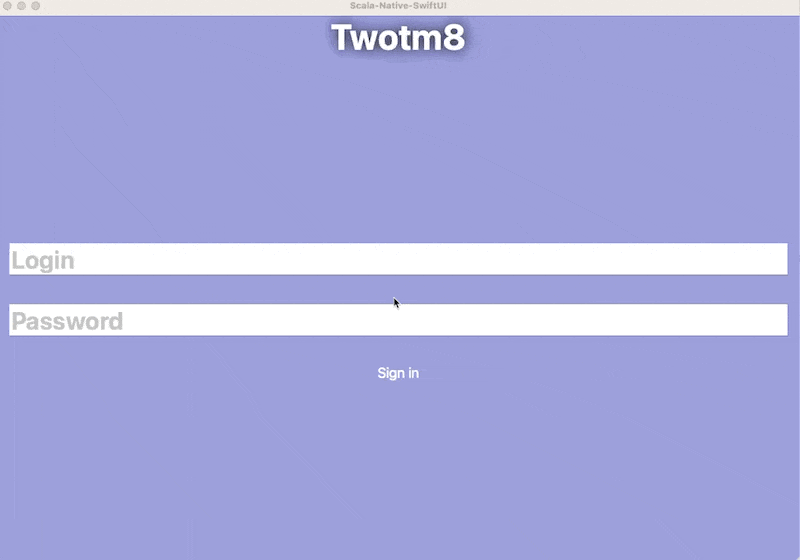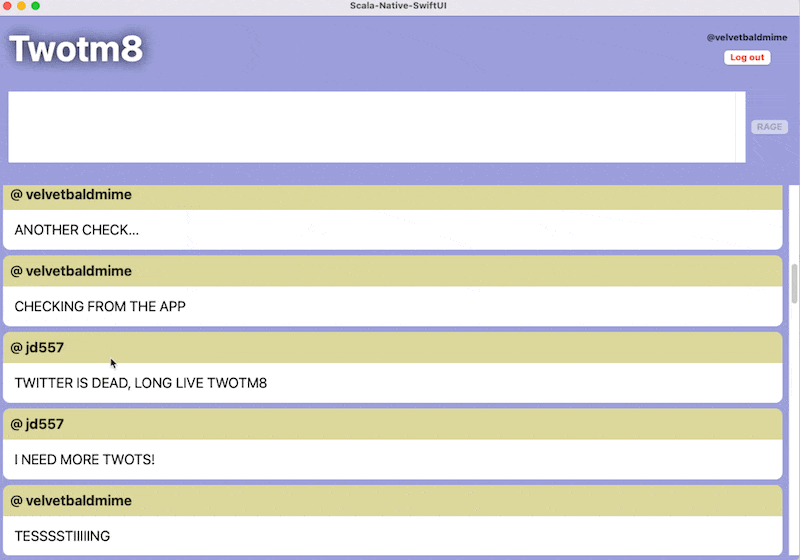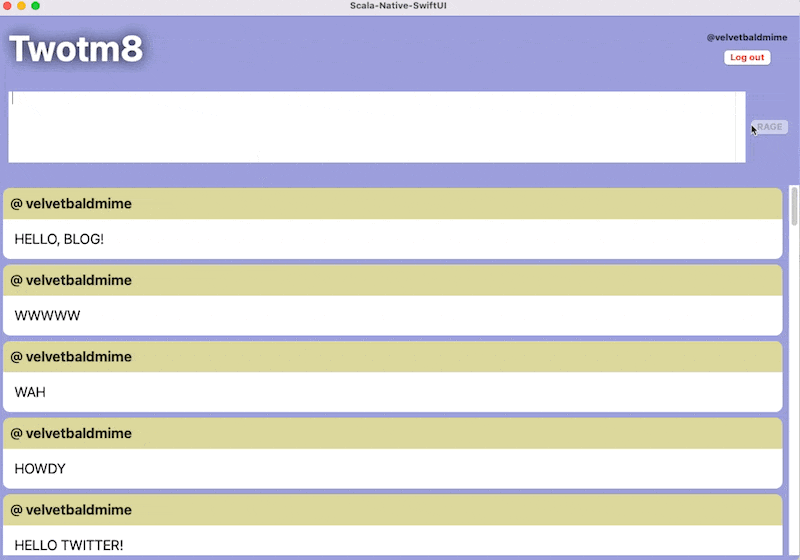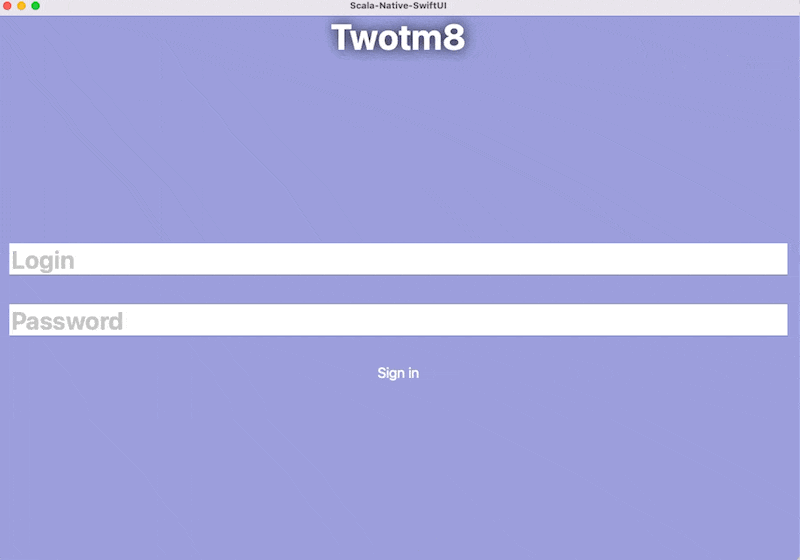
Of course the small experiment I did for the tweet ballooned into a gargantuan exercise in multiple areas where I had zero experience. The joy of putting together languages and components that otherwise refuse to mesh is difficult to explain, but also the explanation might not be necessary - we all at some point rejected "the right tool for the job" dogma, just to shove the tool we can use really really well into a place where it doesn't belong.
Thrill of adventure perhaps, or childish resistance to the bounds of common sense.

Application overview
Our app is very simple, we will attempt to bundle as much as possible inside a single binary of the desktop application.
To do that, we will utilise a relatively recently added ability to build Scala Native projects into shared (or dynamic) or static libraries: https://scala-native.org/en/stable/user/interop.html#exported-methods.

The Twotm8 client module is a simple wrapper around Tapir's client implementation: https://github.com/twotm8-com/twotm8.com/tree/main/client/src/main/scala but I had to provide my own Curl backend as the built-in one doesn't work on Apple Silicon.
We won't be focusing on actually writing the UI components or implementing the logic - all of that is available in the reference repository.
The focus will be the communication protocol we'll implement to merge Swift and Scala.
Communication protocol
As we are no longer working within the confines of the same language, we cannot just call methods across languages and be done with it. We need to come up with a way for the two languages to communicate without losing our own sanity.
Neither Scala Native nor Swift are aware of each other's existence during compilation time. For bidirectional communication between the two language one must respect types, memory semantics, function calling conventions, etc. present in both languages. Functions exported from Scala would need to be called in a particular way, properly laid out and aligned in memory so that their implementation receives the arguments correctly, and puts the response in the right location.
Now add other languages to the mix, like C++, Rust, Go, Zig, Odin, etc. Clearly no compiler team has the resources to support every other language in existence. And those efforts would be meaningless if not reciprocated by the other compiler teams. As things currently stand, we don't have many pairs of languages that can bidirectionally talk to each other without diluting the expressive power of either language.
What we have instead is the C ABI. Both Scala Native and Swift have excellent support for calling and exposing functions that adhere to binary interface widely understood and referred to as C ABI. In short, it's the definition of an interface derived largely from the way C programs communicate with each other when linked into the same binary, or when invoked in a shared library.
Take this C function declaration for example:
int scala_app_hello(char* name, int times);
If all you do is writing C, then it's just that - a function declaration you can call from the rest of your C code. But it's also a description of a binary interface, universally understood across languages. It guarantees that if two different languages see this function declaration, one calling and one implementing, then function invocation will still work even if it's being performed across modules compiled separately, in different languages. And by work we mean it won't segfault and the result will be delivered uncorrupted to the caller.
In Scala Native, we can express the fact that a function with this interface will be available at runtime like this:
import scala.scalanative.unsafe.*
def scala_app_hello(name : CString, times : CInt): CInt = extern
And if we want to expose a Scala Native function as something that can be called from outside using the C calling conventions:
import scala.scalanative.unsafe.*
@exported
def scala_app_hello(name : CString, times : CInt): CInt =
for _ <- 0 to times do
println(s"Hello ${fromCString(name)}")
There are many problems with using C's semantics as the foundation to something as important as the universal communication binary interface between languages and systems. For more details please refer to the excellent post C Isn't a Programming Language Anymore.
In our case, the two main problems about relying on C ABI:
- Expressiveness
- Memory semantics
Let's tackle expressiveness first. Using C ABI necessarily limits us to the types that can be used as part of the exposed interface. Both Scala and Swift have rich type systems with many desirable features that make application development easier.
Those lovely enums? Not anymore, all you have is structs and unions. Vectors with known size? Nope, here's a pointer. Generic classes and methods? Nope. Optional values? Nope, null or bust. Exceptions? Nope, quiet failures and integer return codes are all you get.
As you squeeze the camel through the eye of the needle, what comes out at the other end is no longer a camel, but a complete mess. In the same way attempting to squeeze Scala and Swift types through the C binary interface would be a mess.
Instead, we will reduce the expressiveness of our protocol down from full-blown language semantics, to something less nice, but still much nicer than the raw C ABI - Protobuf. See the dedicated section below.
Now, when it comes to memory semantics, things are not as dire - C ABI says nothing about that. Neither does it check pointers to memory locations being passed around. You can break anything at any time.
This means that we need to think about the meaning of sharing memory between Scala Native and Swift. Both runtimes have automatic memory management - in Scala Native we have garbage collection, akin to what you get on the JVM, and Swift uses automatic reference counting (ARC). Without getting into the details, the important thing to note is that neither language requires you to be aware of when and where the memory is physically allocated - it happens automatically, as well as freeing the memory when it's safe to do so.
"Safe" happens when the program no longer holds references to the allocated object or any of its parts. Unfortunately, C ABI doesn't know anything about either mechanism
of tracking references. All it knows about are primitives (single or multi-byte values that can just be copied without breaking semantics) and pointers to actual
memory of the process. Those pointers are also largely meaningless for either language - even if they refer to actual memory location of, say, an instance of Swift's String,
Scala Native cannot read it automatically - as the memory layouts of Scala's String and Swift's String are different, and what's more - they aren't guaranteed to be the same
across different language versions.
The references also disappear into the sticky ether of C ABI, turning into pointers that aren't tracked by the GCs. So for our system to work well, we need to be able to allocate arbitrary memory on Scala Native's side, and ensure that GC doesn't collect it before the Swift side is done with that memory.
In the next section we will define the actual interface and the semantics that Swift and Scala Native have to follow to ensure the memory is safely managed. Semantics have to be as simple as possible, to ensure that the implementation of binary interface doesn't eclipse in size the actual useful app logic
Binary interface and semantics
There's been about 10 versions in total that I tried, trying to make memory management work on both sides.
In the end I arrived at the interface which looks familiar to some of the other C libraries I worked with, such as libpq.
Here's the full header file we will feed into both Scala Native and Swift. I will describe each marked location in detail:
#ifndef interface_h // 1
#define interface_h
#include <stdbool.h>
#include <stddef.h>
typedef void *ScalaResult; // 2
ScalaResult scala_app_request(const char *data, const int data_len); // 3
bool scala_app_result_ok(const ScalaResult result); // 4
const char *scala_app_get_data(const ScalaResult result); // 5
int scala_app_get_data_length(const ScalaResult result); // 6
bool scala_app_free_result(ScalaResult result); // 7
#ifndef SN_SKIP_INIT
int ScalaNativeInit(void); // 8
#endif
#endif /* interface_h */
-
This is a C trick to avoid declaring the same functions twice if the header file is included in multiple locations that are built together
-
ScalaResultis our opaque type - by defining it asvoid*we indicate that the contents are not supposed to be peeked at as they are laid out according to some internal implementation detail. -
scala_app_requestis our most important function - it will be invoked by Swift, passing a pointer to serialised Protobuf message, and the length in bytes of that message. We don't use null terminated strings and explicitly pass length around. For safety, of course. -
scala_app_result_ok- this function allows Swift to ask about the type of result (error or success) without attempting to deserialise it, which is expensive. -
scala_app_get_data- returns the pointer to the raw Protobuf data. AsScalaResultis an opaque type, Swift side shouldn't be making assumptions as to how the data is laid out - only the Scala side controls that information. -
scala_app_get_data_length- returns the length of the raw Protobuf data. -
scala_app_free_resultthis is a very important method, allowing Swift to indicate that any memory held by Scala side for this particular Result can now be freed up. -
ScalaNativeInitis a special function that the Scala compiler puts into every target that is compiled as a static or shared library. This function has to be invoked before any Scala Native code is executed. This sets up the garbage collector and heap - without calling this function you will get horrible errors. Note that we are gating this definition bySN_SKIP_INITmacro - this is a trick to avoid generating Scala Native bindings for it, while still using a single header file for the source of truth.
Therfore the only bit of behaviour we require from the caller is to free the result after it is no longer needed. Not doing so will result in a memory leak.
Protobuf
Compared to the binary interface, we don't need to invent much here - Protobuf is well studied, it's performant and memory efficient,
and it contains some niceties (such as oneOf and strings/arrays as first class citizens) that make it suitable for our application.
To make the interface suitable for generic handling on both Swift and Scala side, I've arrived at the following rough structure:
message Request {
oneof payload {
Login.Request login = 1;
...
}
}
message Response {
oneof payload {
Login.Response login = 1;
...
}
}
message Error {
ERROR_CODE code = 1;
string message = 2;
}
enum ERROR_CODE {
OTHER = 0;
UNAUTHORIZED = 1;
INVALID_CREDENTIALS = 2;
}
...
The Error, Request, and Response, are the top-level messages - any byte array passed between Scala and Swift will be one of those messages.
The request/response messages are of this structure:
message Login {
message Request {
string login = 1;
string password = 2;
}
message Response { string token = 1; }
}
Without using a service abstraction (available only in GRPC context), it's hard to express the connection between Request and Response for a particular message - which is unfortunate and requires manual handling in the Swift/Scala code.
You can see the full proto file here
Full communication protocol
Here's the simplified interaction diagram (full screen):

Now let's see what it takes to implement both sides of this protocol
Scala protocol implementation
The Scala side of the equation is more difficult than the Swift one. That's because we need to figure out how to manage long lived memory in an efficient way, reducing copying as much as we can.
But first let's scaffold our entry point into the Scala code - the binary interface bindings.
Scala bindings
I am a big believer in relying on single sources of truth to reduce possible drift.
Our binary interface is defined in a header file that Swift handles natively (see below), but Scala Native compiler has no built-in support for automatically binding to C headers.
Conveniently, I maintain a binding generator for Scala 3 Native which supports exports - generating Scala code not for calling the C functions from the header, but rather providing implementations from them.
You can see the fully generated bindings here, and there's a smaller example in the exports documentation on bindgen side.
ScalaResult internal representation
Our protocol makes a clear distinction between errors and responses, and that information
has to be preserved in ScalaResult representation itself, instead of relying on some global storage
of statuses.
Additionally, whatever representation we choose has to be convenient to hold a reference to - so that we can make that reference long lived in the eyes of Scala Native GC.
After not thinking for too long, I arrived at using a scala.Array where first element
is either 1 or 0, depending whether it's an error or not, and the rest of the bytes is
the serialised protobuf data.
My thinking behind it was influenced by the fact that arrays on Scala Native are backed by a single pointer to the data stored continuously, meaning we can return that pointer directly to Swift to read from.
Additionally, using a type that ScalaPB can natively work with requires less code to write. Yay.
In our generated bindings ScalaResult is just an opaque pointer:
opaque type ScalaResult = Ptr[Byte]
object ScalaResult:
given _tag: Tag[ScalaResult] = Tag.Ptr(Tag.Byte)
inline def apply(inline o: Ptr[Byte]): ScalaResult = o
extension (v: ScalaResult)
inline def value: Ptr[Byte] = v
and we will have to write some convenience methods to work with it as an Array and data pointer depending on context.
Protobuf handling
This section is quite simple - we just need to write a generic function that reads a specified Protobuf message from the data we receive in scala_app_request - namely
a pointer to some bytes and number of bytes.
We will be using ScalaPB as it cross-compiles to Scala Native.
Unfortunately, here comes the first inefficiency - Scala Native 0.4 doesn't have a ByteBuffer implementation that is backed by just a pointer and a limit - Scala Native 0.5. introduces a PointerByteBuffer which can be used efficiently to directly read the information from a memory location without copying.
Until SN 0.5 is released, we will have to copy the data into the array:
private[binarybridge] inline def read[A <: scalapb.GeneratedMessage](
comp: GeneratedMessageCompanion[A],
data: Ptr[Byte],
len: Int
): A =
Zone { implicit z =>
// TODO: In Scala Native 0.5 we can avoid this copying by using PointerByteBuffer
val ar = new Array[Byte](len)
libc.memcpy(ar.atUnsafe(0), data, ar.length.toUInt)
comp.parseFrom(ar)
}
We just copy the entire data into an array, and then call ScalaPB to deserialise the desired message from that Array.
The write message is a bit more special, because we want to prepend an error tag:
private inline def write[Msg <: scalapb.GeneratedMessage](
msg: Msg,
isError: Boolean
) =
val ar = new ByteArrayOutputStream(
msg.serializedSize + 1
)
ar.write(if isError then 1 else 0)
msg.writeTo(ar)
ar.toByteArray()
end write
Memory Management
As I mentioned several times, some of the objects allocated by our Scala code should be hidden from GC's watchful eye when they're returned to Swift. GC can't track reference through Swift's internals, and therefore we need to explicitly make it long-lived.
To do that, we introduce a global mutable state, along with all horrors and pains it usually brings:
object GCRoots:
private val references = new java.util.IdentityHashMap[Object, Unit]
def addRoot(o: Object): Unit = references.put(o, ())
def removeRoot(o: Object): Unit = references.remove(o)
def hasRoot(o: Object): Boolean = references.containsKey(o)
override def toString(): String = references.toString
By keeping references to objects in this global state, we can hide/unhide certain Scala values from GC.
Binary interface implementation
Before we start fulfilling the binary contract, let's figure out how to go from opaque ScalaResult to a Array[Byte] that it actually is, and back.
To do that we will use the fact that all Scala objects you have access to in Scala Native are allocated somewhere (on the heap usually), and therefore it's possible to obtain a pointer to where they're actually stored in memory.
Doing so is dangerous and should not be done without a good reason, and the facilities to do so are locked away behind compiler intrinsics for good reasons.
Let's write a couple of helper methods to construct instances of ScalaResult for errors and responses.
import scala.scalanative.runtime.Intrinsics
private inline def makeError(
msg: String,
code: ERROR_CODE = ERROR_CODE.OTHER
): ScalaResult =
val marshalled = write(Error(code, msg), true) // 1
val rawPtr = Intrinsics.castObjectToRawPtr(marshalled) // 2
val arrPtr = scalanative.runtime.fromRawPtr[Byte](
rawPtr
) // 3
GCRoots.addRoot(marshalled) // 4
ScalaResult(arrPtr)
end makeError
-
First we serialise the error message and error code as the Protobuf-generated
Error, this returnsArray[Byte] -
We use intrinsics to obtain the raw pointer (
RawPtr) to the location in memory where thatArray[Byte]actually resides -
We convert the raw pointer into
Ptr[Byte]thatScalaResultrequires -
We add the allocated array to our
GCRoots, meaning that even after this method exists, there will still be a reachable global reference to the array, and GC won't collect it
Constructing a result for a generic protobuf message is just as easy:
private inline def makeResult[T <: scalapb.GeneratedMessage](msg: T) =
val marshalled = write(msg, false)
val arrPtr = scalanative.runtime.fromRawPtr[Byte](
Intrinsics.castObjectToRawPtr(marshalled)
)
GCRoots.addRoot(marshalled)
ScalaResult(arrPtr)
end makeResult
Both those methods go from Array[Byte] to ScalaResult. How do we go back?
private def toByteArray(res: ScalaResult) =
val arr = Intrinsics
.castRawPtrToObject(scalanative.runtime.toRawPtr(res.value))
.asInstanceOf[Array[Byte]]
arr
We use reciprocals of the scary methods we used to convert heap allocated objects to pointers. Note that this operation doesn't copy anything - if the pointer is valid, it's pointing to an already allocated Array in memory.
We now have everything to implement the full binary interface, so let's start slow:
scala_app_result_ok
def scala_app_result_ok(
result: scala_app.binarybridge.aliases.ScalaResult
): Boolean =
toByteArray(result)(0) == 0
Convert to byte array, take first element, ensure it's 0
Getting the protobuf data and length is very easy, as we're just working with a familiar Scala array:
def scala_app_get_data(
result: scala_app.binarybridge.aliases.ScalaResult
): scala.scalanative.unsafe.CString =
toByteArray(result).atUnsafe(1)
def scala_app_get_data_length(
result: scala_app.binarybridge.aliases.ScalaResult
): scala.scalanative.unsafe.CInt =
toByteArray(result).length - 1
atUnsafe is a Scala Native-specific method on the Array which gives a pointer to the data
at given index, without performing boundary checks (so slightly faster than .at which does the same but with checks).
Now let's implement scala_app_free_result which is there to ensure that Swift has a way
to tell Scala code to free up memory held by a particular ScalaResult instance
override def scala_app_free_result(res: ScalaResult) =
if res.value != null then
val obj =
Intrinsics.castRawPtrToObject(scalanative.runtime.toRawPtr(res.value)) // 1
if GCRoots.hasRoot(obj) then // 2
scribe.debug(s"Freeing result ${res}")
GCRoots.removeRoot(obj) // 3
true
else
scribe.debug(
s"Attempted to free result ${res}, but it's already been freed or doesn't exist"
)
false
end if
else true
-
Cast the pointer to a Scala object
-
Check the object is actually in GCRoots (meaning that this
ScalaResulthas not been deallocated yet, it's live) -
Remove the root - which lets GC know that the last reference to this object has been removed
At this point you are ready to actually implement the meat of our interface - scala_app_request:
override def scala_app_request(
data: Ptr[Byte],
data_len: Int
): ScalaResult =
val msg = read(protocol.Request, data, data_len)
handleRequest(msg) match
case Answer.Error(msg, code) =>
makeError(msg, code)
case Answer.Ok(value) =>
makeResult(value)
end match
end scala_app_request
The actual implementation I have is the same, it just has a bit more error handling, you can find it here.
In this snippet I just use a custom ADT to define a result of the operation:
enum Answer:
case Error(msg: String, code: protocol.ERROR_CODE = protocol.ERROR_CODE.OTHER)
case Ok[T <: GeneratedMessage](value: T)
and handleRequest is effectively protocol.Request => Answer function, which implements our actual logic.
Believe it or not, but we're done with the Scala side of the protocol! Now how do we even call these interfaces from Swift?
Swift protocol implementation
In this section we will implement all the custom logic required to communicate through our binary interface from Swift side. The Protobof implementation we will use is the official Apple's one - SwiftProtobuf.
Please note that I have 0 experience with Swift, and everything here was cobbled together through trial, error, and begging search engines for examples. If you see a way to improve the code, please create an issue on the repository, or submit a PR directly.
Swift bindings
If you have read the Zig post about this same subject, you will know that Swift transparently generates bindings for C headers if they're placed in the correct location (XCFramework, also covered in the post), and contain a module map file:
module.modulemap
module ScalaKit {
umbrella header "binary_interface.h"
export *
}
The generated bindings will use all of the Swift's facilities to work with unsafe memory.
Memory Management
Because the ownership of operation results is handled by the Scala side, our Swift code doesn't need to do anything special with regards to memory - as long as we respect the semantics of the binary protocol, there shouldn't be any leaks.
Binary interface implementation
We will hide the details of protobuf and binary interfaces being different, and only expose a single generic method that allows sending a protobuf Request and getting either the Response back, or throwing an error.
Here's the entire implementation:
enum ProtocolError: Swift.Error {
case failure(String)
case parsing(String)
}
static func writeToWire<T: SwiftProtobuf.Message, R: SwiftProtobuf.Message>(msg: T) throws -> R? {
let contents = try msg.serializedData() // 1
return try contents.withUnsafeBytes { (bytes: UnsafePointer<CChar>) in // 2
let result = ScalaKit.scala_app_request(bytes, Int32(contents.count)) // 3
defer {
ScalaKit.scala_app_free_result(result) // 4
}
if let err = getError(result: result) { // 5
throw ProtocolError.failure(err)
} else {
let messageBytes = ScalaKit.scala_app_get_data(result)
let messageSize = ScalaKit.scala_app_get_data_length(result)
let buffer = UnsafeBufferPointer(start: messageBytes, count: Int(messageSize)) // 6
do {
let resp = try R(serializedData: Data(buffer: buffer)) // 7
return resp
} catch {
throw ProtocolError.parsing(error.localizedDescription)
}
}
}
}
-
This is the SwiftProtobuf's method to serialise data into an byte array
-
We use Swift's built-in mechanisms to work with unsafe memory and pointers, and request an actual pointer to array data, so we can pass it to the binary interface
-
We invoke the binary interface method
scala_app_request- the methods from the header will be put inside theScalaKitmodule, as that's the name we chose inmodule.modulemapfile -
Using Swift's
defer, we ensure thatscala_app_free_resultis called after the scope exits - regardless of what happens -
If the result is erroneous, throw it (
getErrorimplementation is below) -
After getting the message bytes and length, we create a Swift's buffer pointer with fixed size
-
This is SwiftProtobuf's way of reading the message from built-in
Dataconstruct that we initialised with our byte buffer
The getError method does pretty much the same things:
static func getError(result: ScalaResult?) -> String? {
if(!ScalaKit.scala_app_result_ok(result)) {
let errorBytes = ScalaKit.scala_app_get_data(result)
let errorSize = ScalaKit.scala_app_get_data_length(result)
let buffer = UnsafeBufferPointer(start: errorBytes, count: Int(errorSize))
do {
let err = try Error(serializedData: Data(buffer: buffer))
return err.message
} catch {
return "Failed to deserialise error message: \(error)"
}
}
else { return nil }
}
And here's an example of how to use this generic writeToWire function:
enum Res {
case Ok(Response.OneOf_Payload)
case Err(ProtocolError)
}
static func sendRequest(request: Request.OneOf_Payload) -> Res {
let req = Request.with{
$0.payload = request
}
do {
let x: Response? = try writeToWire(msg: req)
if let resp = x {
if let payload = resp.payload {
return Res.Ok(payload)
} else {
return Res.Err(ProtocolError.parsing("response payload cannot be empty"))
}
} else {
return Res.Err(ProtocolError.parsing("empty response"))
}
} catch let e as ProtocolError {
return Res.Err(e)
} catch {
return Res.Err(ProtocolError.failure("Unknown error: \(error.localizedDescription)"))
}
}
This example is written specifically to handle the shape of the Protobuf protocol in this application, so it doesn't
generalise nearly as well as the writeToWire.
Writing application logic
After long day of writing interfaces and binary protocols, I want to rest by the fire and finally write some business logic, so I can really deliver some value to my shareholders.
Scala
Without providing much commentary, here's an excerpt from the handleRequest function where the logic really lives:
case Req.Login(value) =>
val login = value.login.trim
if login.isEmpty then Answer.Error("empty login!")
else if value.password.isEmpty then Answer.Error("empty password!")
else
state.client.login(Nickname(login), Password(value.password)) match
case Left(ErrorInfo.InvalidCredentials()) =>
Answer.Error("invalid credentials", ERROR_CODE.INVALID_CREDENTIALS)
case Left(other) => Answer.Error(other.message)
case Right(value) =>
state.respond(
Res.Login(
Login.Response(value.jwt.raw)
)
)
end if
Apart form using slightly clunky protobuf payloads that were generated, it seems like pretty normal Scala code, that could manage state, make calls, log things, etc.
And it's implemented entirely in terms of protobuf definitions - an interface portable across languages and implementations.
SwiftUI
Again, without much commentary, here's the SwiftUI code that will eventually trigger the login logic above:
struct LoginView: View {
@SwiftUI.State private var username: String = ""
@SwiftUI.State private var password: String = ""
@SwiftUI.State private var errorMessage: String = ""
private let vm: ViewModel;
// ...
TextField("Login", text: $username).padding().fontWeight(.bold).font(.system(size: 35))
SecureField("Password", text: $password).padding().fontWeight(.bold).font(.system(size: 35))
Button(action: logIn) { // connect this button with `logIn` function below
Text("Sign in").frame(minWidth: 0, maxWidth: .infinity)
}.styledButton().handHover()
// ...
func logIn() {
let resp = Interop.sendRequest(request: .login(Login.Request.with {
$0.login = username
$0.password = password
}))
if case .Ok(.login(let response)) = resp {
vm.tokenAcquired(token: response.token, source: .login)
}
if case .Err(let msg) = resp {
errorMessage = msg.msg()
}
}
Build
Ultimately, we need to bring our entire Scala monster to the place where SwiftUI happens - and that's Xcode.
Xcode has a lot of good features, but ultimately it's cut from the same cloth as my nightmares - it's a huge UI encompassing non-declarative build definition spread out across dozens of toggles, fields, and tabs. Configuring it without prior knowledge has been frustrating.
In the end, to package the full application, we will need all of the steps mentioned in the Zig post - plus some additional ones to regenerate bindings and protobuf definitions.
- Generate Scala code for binary interface bindings
- Generate Scala code for Protobuf definitions
- Build a static library out of the Scala code
- Bundle the static library from (3) with the static libraries of its dependencies (using libtool): curl, libidn2, etc., mostly needed for Tapir to run HTTP requests.
- Generate XCFramework - a folder with particular layout which contains the header files and library files that Xcode will link as part of the build
- On top of that, that XCFramework needs to physically be dragged into our project in the UI for Xcode to even consider it..
- Generate Swift code for Protobuf definitions
- (finally) Build Xcode project
And that doesn't include the signing of the app, which I refused to continue with after an attempt wiped by default login keychain.
I won't bore you with details of this entire pipeline, you can see the entire definition as a Mill build file
Xcode configuration
There were several things I had to in Xcode as well:
- Enable "Network > Outgoing connections (Client)" under Signing & Capabilities (without it you get super cryptic runtime errors)
- Adding
-lc++ -liconvflags under "Linking - General > Other Linker flags" - without-lc++you would get linktime failures because Scala Native runtime needs C++'s exceptions runtime. And-liconvis required because you cannot install static iconv library on Macos (i.e. in vcpkg it's an empty port, containing no files) - it's available by default but you have to request it via linker flags
And probably something else, it's hard to memorise things when you're clicking randomly
Future plans
Now that I have conquered the Apple platform and ecosystem it's time to reach out to other markets.
The presented approach will work similarly if I were to build a Windows application - the Scala core will remain untouched, and both C# and F# (for modern Windows development? may be? WinForms? WinUI? Win32?) have the ability to call functions over C ABI.
The build process will be slightly different, but overall I believe it's possible.
For something like Gtk, we can still reuse most of the Scala logic, we just won't need the Protobuf layer at all - Gtk is written in C and can be invoked directly from Scala Native, see https://github.com/indoorvivants/scala-native-gtk-bindings.
Conclusion
That's all I have for you today, it's been a complicated project mostly due to the amount of moving parts involved.
I can't say for certain if this approach has legs - for an application like this one the Scala part of the application contains almost no logic. But for a more complicated one, or one that deals with file system or runs some particular validation logic, this could be worth it to bring native UI performance with each platform with minimal duplication of application logic.
I won't know until I've at last implemented it for another platform. That said, it's been a lot of fun seeing all the pieces fall in place and seeing a finally working application. For that alone I can recommend doing this.