TL;DR
- We are deploying an app to Cloudflare using Scala.js
- We are using ScalablyTyped
- We are using Scala 3 heavily
- Code on Github
- Deployed app
- Cloudflare API bindings
Welcome to the "Put ma Scala on yo cloud" series
I want to say that I'm kicking off a blog series, but even I don't believe that.
If I did, the series would be about finding and documenting simplest possible way to deploy some Scala code into the mythical "cloud". There are several rules:
-
Code must do something non-trivial
"Hello world" doesn't cut it. Definition is vague, but ideally there's some database access going on along with processing user's request.
-
Deployed code must expose a HTTP API
Which must be accessible from the outside world. Simply logging to some ephemeral storage won't count.
-
Deploying should be simple
Simple is a relative term, so I will measure it in two quantities I know best
┌─────────┐ │Number of│ │ mouse │ │ clicks │ └─────────┘ ▲ │ ┌───┐ │ │Bad│ │ └───┘ │ │ │ │ │ │ │ │ ┌────┐ ┌──────────┐ │ │Good│ │ Lines of │ │ └────┘ │ YAML │ └─────────────────────────────▶ └──────────┘ -
Deploying from Github
As these serve mostly education purpose for me, I don't want to set up any private infrastructure or battle permissions.
And with my limited YAML ability, I should be able to automate deploys from Github Actions.
-
Apps must be in Scala
Doesn't matter if Scala is natively supported, or if Scala is compiled to a supported language/architecture.
While I'm not averse to learning (or re-learning) any language if I have the need, I don't have any urgent requirements to get the app out there, so I might as well use what I know, like, and can maintain.
Quick intro to Cloudflare platform
I'm reconstructing the history based on Cloudflare's blog, I wasn't paying attention at the time when the ancient scrolls were written
At first, there were Cloudflare Workers - serverless execution environment for JavaScript apps, with minimal configuration and no infrastructure to manage.
Then, Cloudflare Pages were added, to deploy frontend applications, optimised to work with popular JS libraries and frameworks, with minimal setup, preview environments etc.
The Pages could be used in conjunction with Workers to create a full-stack application. JavaScript and TypeScript are the only supported languages. Still, deployment of Pages and Workers were separate.
As of recently, Cloudflare Functions Beta was released.
Cloudflare Functions are built on top of Workers (more on that later), and use the same execution environment. Main difference is how the functions are defined, and how tightly integrated they are with Cloudflare Pages.
In this post we will focus on Cloudflare Functions.
Cloudflare Pages setup
As Cloudflare Functions are designed to be the backend side of a static site deployment, let's go over the setup for Cloudflare Pages first.
-
Register your account: https://pages.cloudflare.com/
There is a free plan available, which requires no credit card and should be plenty for any experiments
-
Connect your Github/Gitlab account.
This is as simple as connecting with Cloudflare's GH app
-
Choose a repository to set up
You can configure which repositories the app has access to, which then makes them appear in Cloudflare interface.
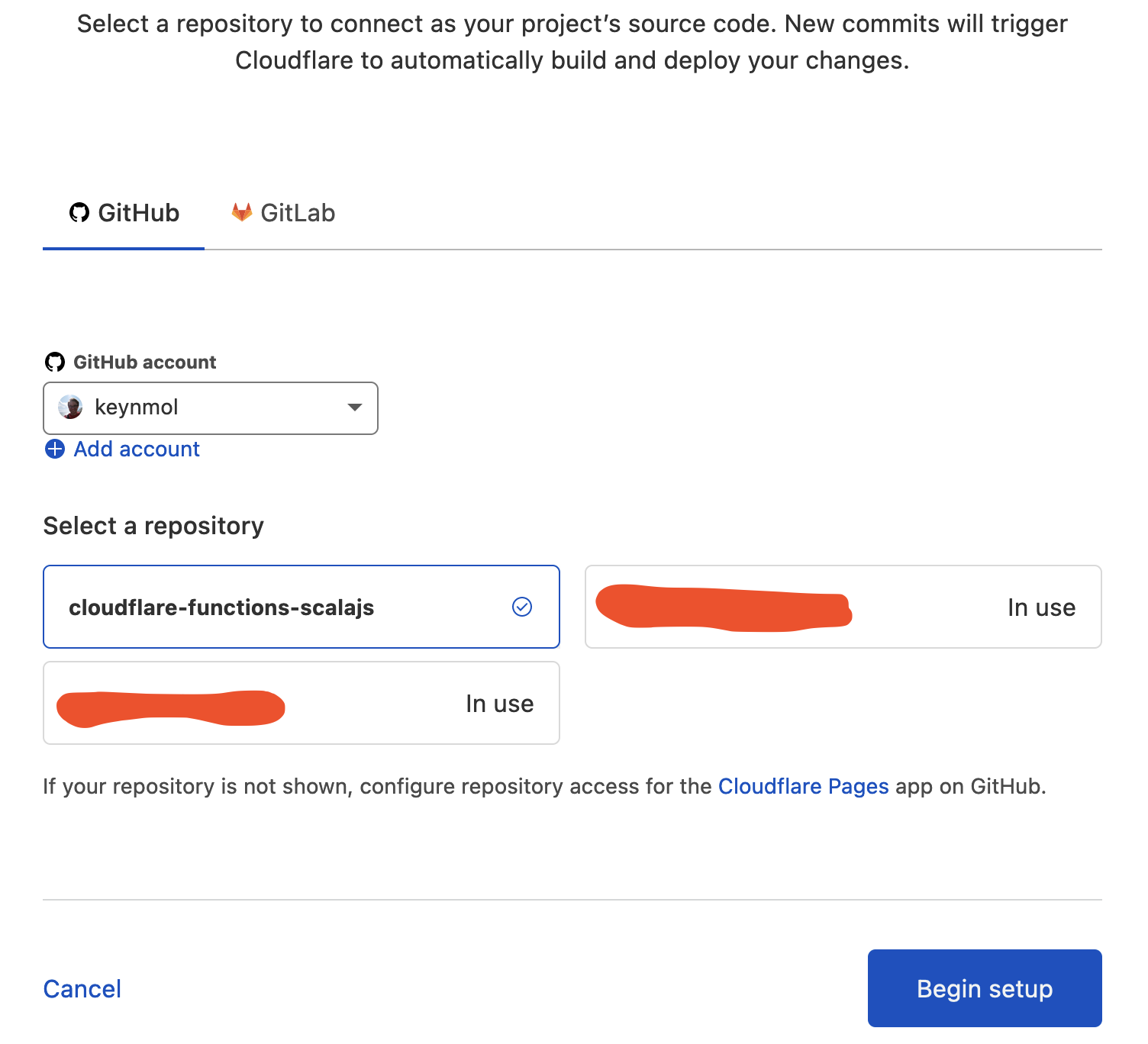
-
Choose a branch from which to the app will be deployed
App code pushed to this branch will be used to deploy the app on the main address assigned to you project.
Cloudflare's deployment process is pull-based - rather than building some container/archive/fat jar/fat
.jsfile, the build process will run on Cloudflare's infrastructure.Other branches will be designated for preview environments.

-
Configure how the app is built
This section allows you to let Cloudflare know what commands to run and what files to collect to produce the fully assembled version of the app.
In the context of Cloudflare Pages and Functions, think of "fully assembled version of the app" as "final set of static assets + the server-side JavaScript files".
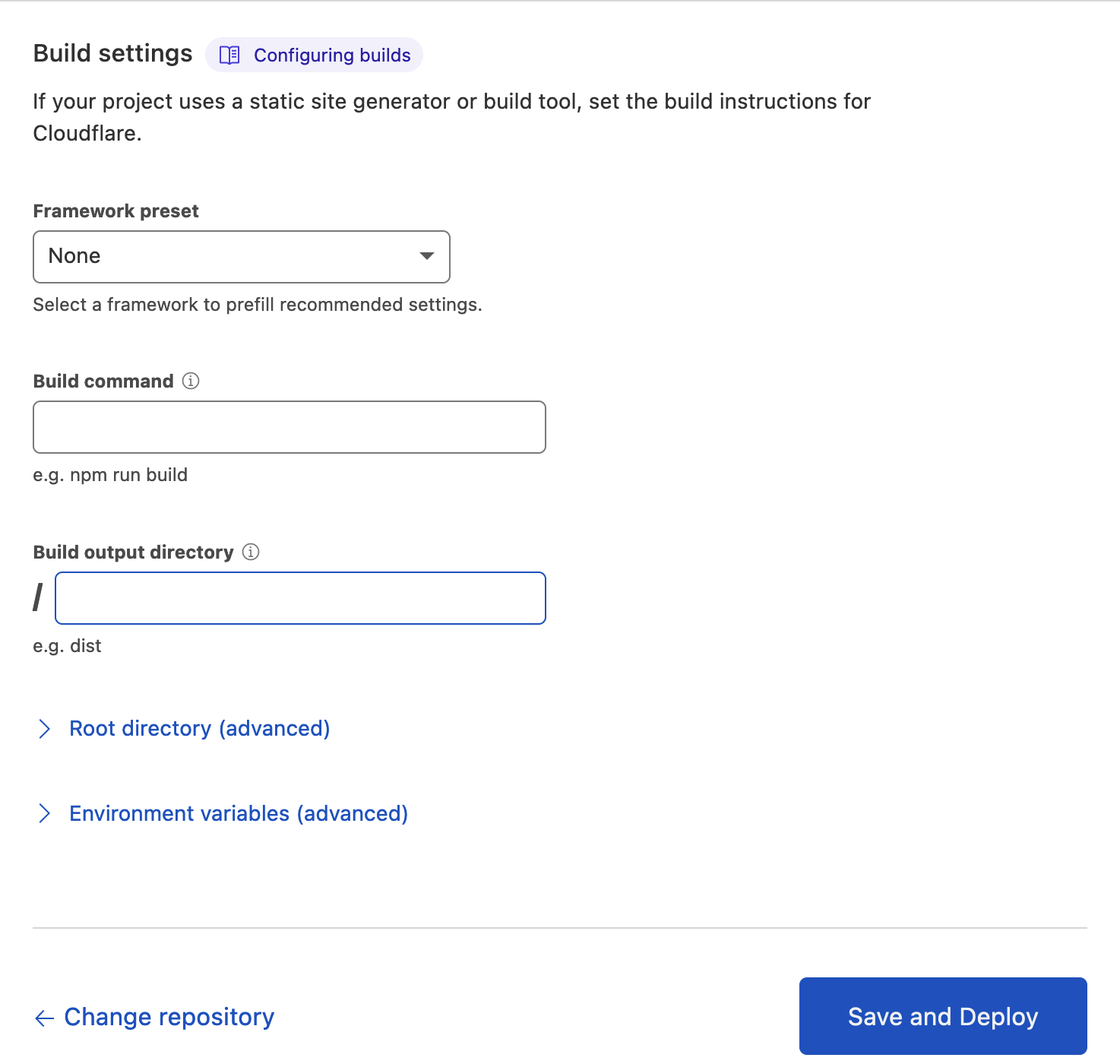
-
Framework preset – sadly, we will be taking the road less traveled, and using Scala.js, which is not on the list
-
Build command - we will come back to this later, but this is the command invoked by Cloudflare's build environment (not execution environment) to build your app.
Leave it empty for now
-
Build output directory – this is where Cloudflare will expect a fully built set of static assets your site consists of. By default it's root folder, and we won't change this.
-
That's it! If everything is configured correctly, we should be able to push static files to our repository and see them deployed to Pages.
Deploying static pages
As we are starting out with an empty repository, the first thing we will commit is a simple HTML page (./test.html):
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>A Basic HTML5 Template</title>
</head>
<body>
<h1>Hello!</h1>
</body>
</html>
After we commit and push to our repository, the Cloudflare deployment immediately kicks off
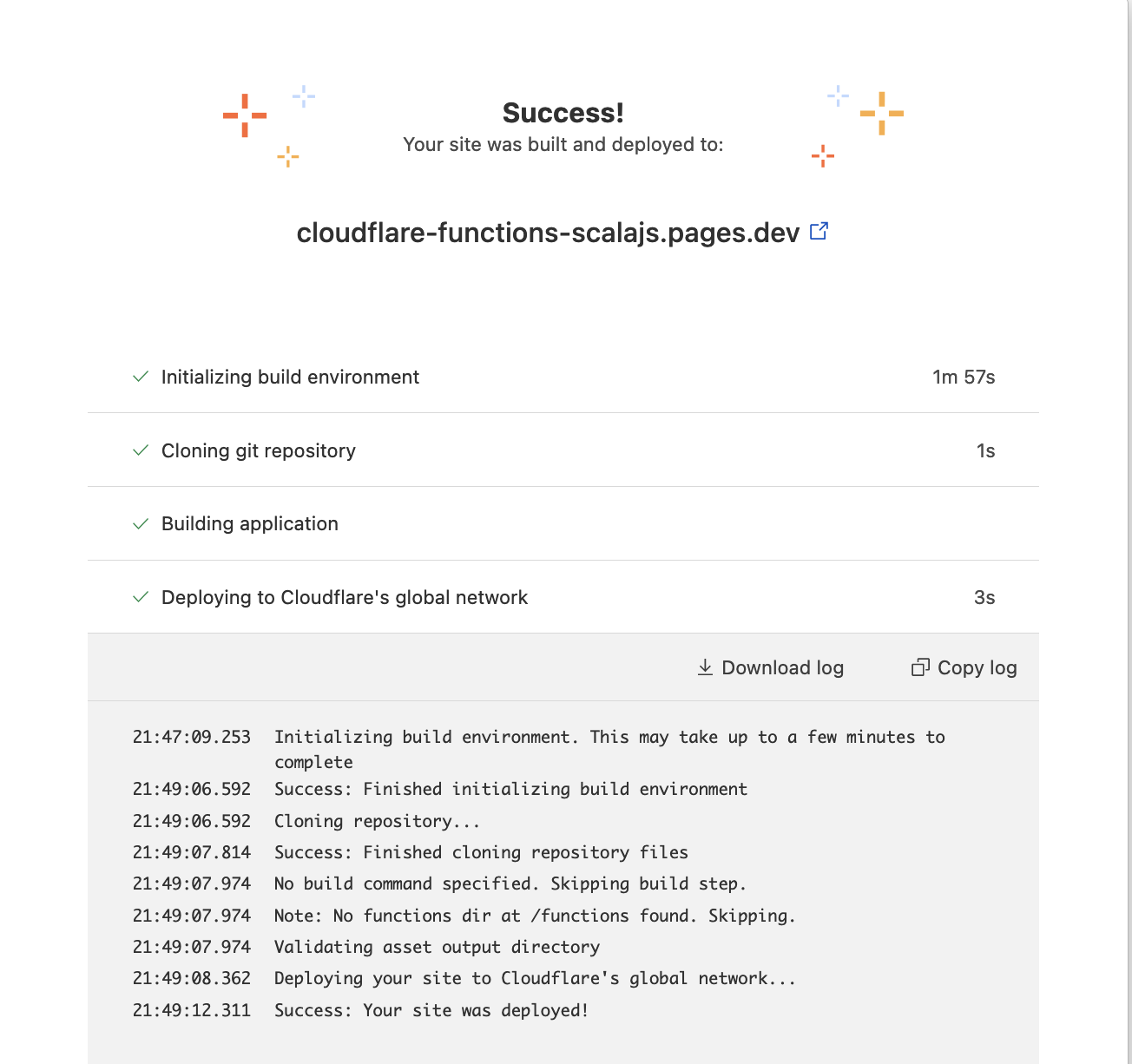
And we can verify (with curl) that indeed our html page has been deployed:
$ curl https://cloudflare-functions-scalajs.pages.dev/test
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>A Basic HTML5 Template</title>
</head>
<body>
<h1>Hello!</h1>
</body>
</html>
Excellent, now writing blog posts in static html seems easier than ever! (just kidding, go and write your own static generator that you will never use, it's fun).
Now that we have our static site deployed, let's look into how Functions are deployed in more detail.
Deploying Cloudflare Functions
As with many things on the Cloudflare platform, the goal seems to be reducing the amount of explicit configuration you have to do.
First important thing you should know is that your serverless functions will
be deployed from the /functions folder at the root of your repository.
That is not configurable.
Second important thing is that your functions are defined in .js or .ts files (JavasScript or TypeScript, that's it). And the folder structure is very important.
Let's say our repository is structured like this:
❯ tree
.
├── functions
│ ├── admin
│ │ └── edit.ts
│ └── api
│ ├── bla
│ │ └── test.js
│ └── hello.js
└── test.html
When you deploy this, the following things will happen (let's assume your Pages deployment is at https://<PAGES_URL>.dev):
-
https://<PAGES_URL>.dev/testwill servetest.htmlpage -
https://<PAGES_URL>.dev/admin/editbecomes a server-side endpoint, which executes the contents of/functions/admin/edit.tsfile -
https://<PAGES_URL>.dev/api/bla/testbecomes a server-side endpoint, which executes the contents of/functions/api/bla/test.jsfile -
https://<PAGES_URL>.dev/api/hellobecomes a server-side endpoint, which executes the contents of/functions/api/hello.jsfile
That is, the structure of the /functions folder will determine the structure
of the endpoints in the deployed API.
The contents of the individual JS/TS files will determine the endpoint's logic and the HTTP method they will respond to.
Writing Functions in JavaScript
Now that we know how function files translate to API paths, let's write some JavaScript.
❯ tree
.
├── functions
│ ├── do_something.js
│ ├── do_something_with_get.js
│ └── do_something_with_post.js
└── test.html
// ./functions/do_something.js
export async function onRequest(request) {
return new Response(`This is any request really`);
}
// ./functions/do_something_with_get.js
export async function onRequestGet(request) {
return new Response(`This is a GET request`);
}
// ./functions/do_something_with_post.js
export async function onRequestPost(request) {
return new Response(`This is a POST request`);
}
Don't worry, I also don't know JavaScript and have no idea what async could possibly mean here.
The names of these functions are significant.
- Function named
onRequestwill respond to any HTTP verb - Function named
onRequestGetwill respond only to GET verb - Function named
onRequestPostwill respond only to POST verb etc.
Remember, that endpoint's path is determined by filename, not function name.
So, let's commit these files and push to the branch. After deployment complete, you can already see the router that Cloudflare reconstructs from the file paths:
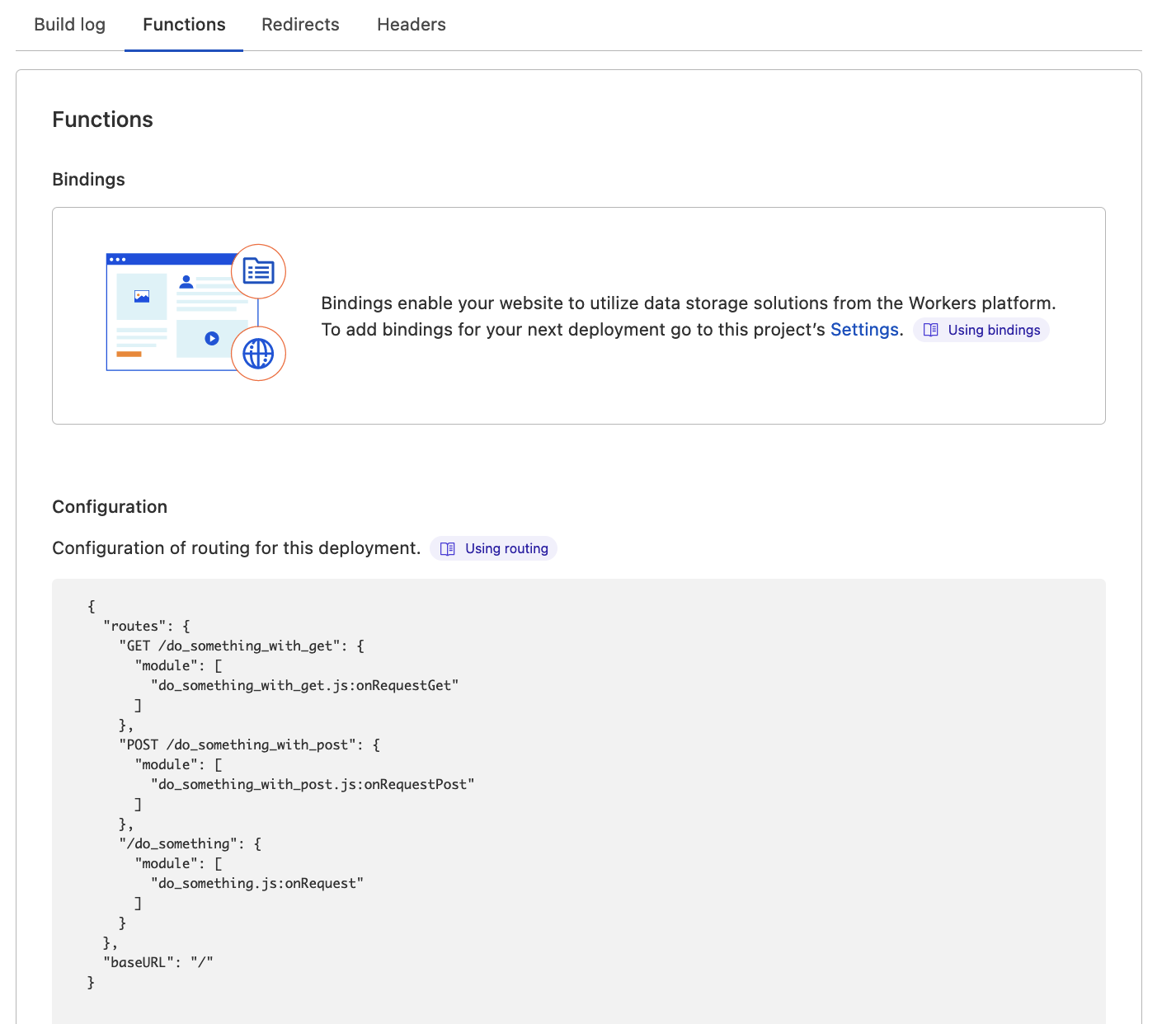
And our endpoints do respond:
❯ curl https://cloudflare-functions-scalajs.pages.dev/do_something
This is any request really
❯ curl https://cloudflare-functions-scalajs.pages.dev/do_something_with_get
This is a GET request
❯ curl -XPOST https://cloudflare-functions-scalajs.pages.dev/do_something_with_post
This is a POST request
Attempting to use an incorrect HTTP verb will result in a 405 Method Not Allowed
response.
Excellent, now that we're done with the thing Cloudflare Functions were designed to do, let's move on to my favourite topic.
Scala-shaped peg into a JS-shaped hole
No surprise, we will compile our Scala code to JavaScript using Scala.js.
Full introduction to Scala.js will have to wait (but do have a read of the website!), but let's start gently
It would be desirable to take advantage of the structural API definition that Cloudflare Functions support.
To do so, our build must produce individual JS files that will define the functions we want to become API endpoints.
Gladly, there is a way to tell Scala.js that we want to export some functions as individual modules (in an ECMAScript modules sense).
Using scala-cli
One alternative I considered is to use the excellent scala-cli, which supports Scala.js and has a package command that
seems to be tailor made for this usage.
Unfortunately, in its current form, package is designed to produce a single runnable file, with an entry method (your def main(args: Array[String]) = ...).
In the context of Cloudflare Functions, there's no single entry point. Cloudflare forms a single worker out of our disjoint API functions, but that worker is then submitted to the runtime - the entry point is opaque to us.
Attempting to produce multiple modules using scala-cli will fail, for now. An issue was created and is now on scala-cli authors' radar.
I will make an update to this blogpost once that feature is released. Then it will be quite cool - self-contained single-file scripts that are only 1 scala-cli command away from being turned into Cloudflare APIs? Damn right, that's hot
Using SBT
The full power of Scala.js integration can be used from within SBT and that should satisfy any needs we have with regards to output/module structure.
So let's begin by setting up a barebones Scala.js project with SBT:
// ./project/build.properties
sbt.version = 1.6.1
// ./project/plugins.sbt
addSbtPlugin("org.scala-js" % "sbt-scalajs" % "1.8.0")
// ./build.sbt
name := "cloudflare-test"
scalaVersion := "3.1.1"
enablePlugins(ScalaJSPlugin)
With this setup, the location of produced *.js files will depend on the
build command we run:
-
fastLinkJS- quick mode, with no optimisationstarget/scala-3.1.1/cloudflare-test-fastopt
-
fullLinkJS- slower, full set of optimisationstarget/scala-3.1.1/cloudflare-test-opt
Emitting JavaScript modules
By default, Scala.js will produce a single JavaScript file, with any exports or entry points you've identified in your Scala code.
While this may be preferred for browser applications or CLI tools, in our case we want to export individual functions as separate files.
To do this, let's configure the Scala.js linker to output ECMAScript modules:
// ./build.sbt
name := "cloudflare-test"
scalaVersion := "3.1.1"
enablePlugins(ScalaJSPlugin)
scalaJSLinkerConfig ~= { conf =>
conf
.withModuleKind(ModuleKind.ESModule) // sic!
}
You can read more about modules and this particular setting on the scala-js dedicated page
This will instruct Scala.js to output individual ES modules, as long as we tell Scala.js compiler
- what the modules are
- how to export them
To keep things simple, let's define two very simple functions:
// ./src/main/scala/app.scala
package app
import scala.scalajs.js.annotation.JSExportTopLevel
@JSExportTopLevel(name = "onRequest", moduleID = "request_headers")
def request_headers(context: Any) =
println(context)
"hello"
@JSExportTopLevel(name = "onRequestGet", moduleID = "request_method")
def request_method(context: Any) =
println(context)
"bye"
Let's unpack:
- We're marking two functions with the
JSExportTopLevelannotation provided by Scala.js - Those annotations are configured to
- Export
request_headersScala functions as aonRequestJS function in a module namedrequest_headers.js - Export
request_methodScala functions as aonRequestGetJS function in a module namedrequest_method.js
- Export
Once we run it, say, sbt fastLinkJS, we can take a look at the files produced:
❯ exa target/scala-3.1.1/cloudflare-test-fastopt --no-user -l
.rw-r--r-- 79k 26 Jan 18:37 internal-0e1e8a7b68809aecf0131c695a7a6be34fa430dd.js
.rw-r--r-- 43k 26 Jan 18:37 internal-0e1e8a7b68809aecf0131c695a7a6be34fa430dd.js.map
.rw-r--r-- 405 26 Jan 18:37 request_headers.js
.rw-r--r-- 387 26 Jan 18:37 request_headers.js.map
.rw-r--r-- 403 26 Jan 18:37 request_method.js
.rw-r--r-- 386 26 Jan 18:37 request_method.js.map
The internal-<mumbo-jumbo> file contains the code shared by both modules,
and both request_method and request_headers reference it.
❯ cat target/scala-3.1.1/cloudflare-test-fastopt/request_headers.js
'use strict';
import * as $j_internal$002d0e1e8a7b68809aecf0131c695a7a6be34fa430dd from "./internal-0e1e8a7b68809aecf0131c695a7a6be34fa430dd.js";
let $e_onRequest = (function(arg) {
var prep0 = arg;
return $j_internal$002d0e1e8a7b68809aecf0131c695a7a6be34fa430dd.$m_Lapp_app$package$().request_headers__O__T(prep0)
});
export { $e_onRequest as onRequest };
//# sourceMappingURL=request_headers.js.map
The penultimate line is very important:
export { $e_onRequest as onRequest };
This exports an internal function generated by Scala.js and renames it to onRequest, according to our annotation.
Let's do a quick test by copying the JS files generated into the /functions
folder that we know works with regular JS files:
❯ cp target/scala-3.1.1/cloudflare-test-fastopt/*.js /functions
❯ git add functions/*.js
❯ git commit -m 'First foray into functions'
❯ git push origin $(git branch --show-current)
After the deployment has completed, let's see if our function worked:
❯ curl -f https://cloudflare-functions-scalajs.pages.dev/request_method
curl: (22) The requested URL returned error: 500
Oh-oh! And if you vist the page itself, it would've given you a very loud error page.
Let's see what's up. First of all, our function was definitely deployed and correctly recognised:
{
"routes": {
"GET /do_something_with_get": {
"module": [
"do_something_with_get.js:onRequestGet"
]
},
"GET /request_method": {
"module": [
"request_method.js:onRequestGet"
]
},
"POST /do_something_with_post": {
"module": [
"do_something_with_post.js:onRequestPost"
]
},
"/do_something": {
"module": [
"do_something.js:onRequest"
]
},
"/request_headers": {
"module": [
"request_headers.js:onRequest"
]
}
},
"baseURL": "/"
}
But what we failed to recognise is that the functions deployed to this platform must conform to a particular type signature.
As the Workers' runtime must construct them, pass correct arguments, and interpret the response correctly.
In our case we just returned a String from the function, which clearly isn't enough.
Before we find a solution to this problem, let's answer another question - is there a way to get better feedback, and, more importantly, faster feedback?
Local development
While the deployment procedure is quite straightforward and requires no extra setup apart from pushing to Git repository, the feedback time is not great - takes 2 minutes for the build to finish, and that's without any deployment script running.
What makes it worse is that Functions is in public beta, and as such... has no logs! No way for you to identify a problem if it happened on a deployed instance. Cloudflare promises logs once Functions become GA.
Do not despair, for Cloudflare have a special tool to aid local development: Wrangler.
Wrangler is a Node.js tool designed to simulate your Workers/Pages/Functions environment with reasonable fidelity to how it will operate when deployed.
After installing it, we can start a local environment in a local folder of our project by just simply running this command:
❯ wrangler pages dev .
Compiling worker to "/var/folders/my/drt5584s2w59ncgxgxpq7v040000gn/T/functionsWorker.js"
# ...
Finished in 98ms.
Serving at http://127.0.0.1:8788/
And if open the http://127.0.0.1:8788/request_method URL, we are presented
with a much more informative error page:
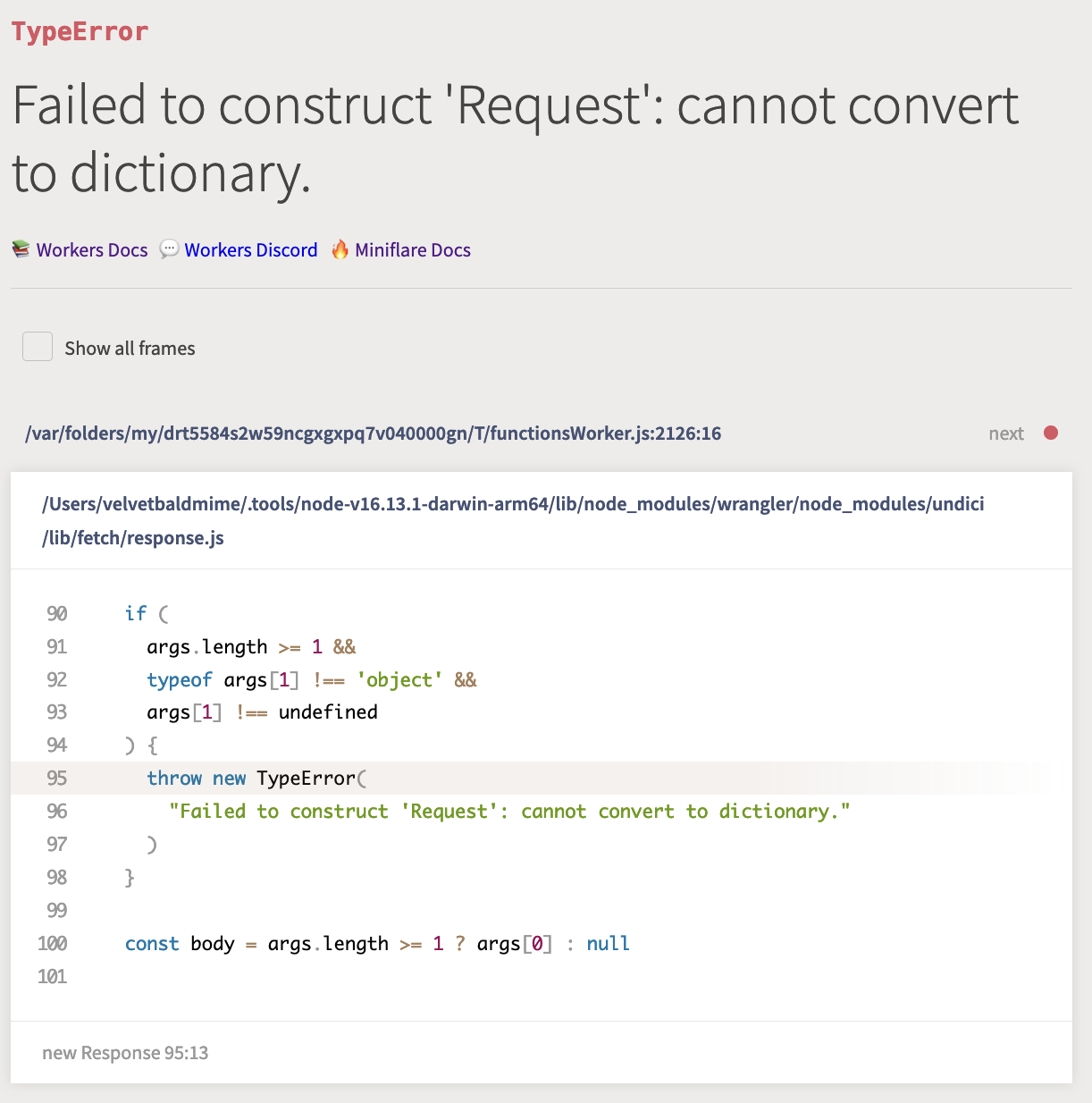
Which seems to give a soft confirmation to our theory - the function could not be invoked because the arguments were of the wrong type.
See, JavaScript does have types!
If Any is a wrong type of Cloudflare Functions parameters, how do we find out what is?
TypeScript types definition
Turns out, Cloudflare are publishing the typed definitions for the entire set of Worker-related APIs.
The definitions are publicly available, published to NPM, and are distributed as TypeScript declarations.
And if we stare at the definitions long enough, we can find the definition of the full type for individual Functions:
declare type PagesFunction<
Env = unknown,
Params extends string = any,
Data extends Record<string, unknown> = Record<string, unknown>
> = (context: EventContext<Env, Params, Data>) => Response | Promise<Response>;
Where EventContext refers to this data structure:
type EventContext<Env, P extends string, Data> = {
request: Request;
waitUntil: (promise: Promise<any>) => void;
next: (input?: Request | string, init?: RequestInit) => Promise<Response>;
env: Env & { ASSETS: { fetch: typeof fetch } };
params: Params<P>;
data: Data;
};
Don't worry if you don't understand TS interface - neither do I. What's important to understand is that each Cloudflare Function is essentially a
(context: EventContext<Env, Params, Data>) => Response | Promise<Response>;
Where the context parameter is a JavaScript Record which must have
certain fields, like request, of type Request, which is where our original error
comes from!
Now, it's certainly possible to stare at these interfaces long enough and use built-in functionality of Scala.js to manually re-create interfaces in Scala that just about match what the runtime will expect.
But we won't do that. Instead, we will stand proudly on the shoulder of giants, namely SBT plugin called ScalablyTyped.
ScalablyTyped, work your magic!
ScalablyTyped is an absolutely wonderful plugin for SBT (and as of recently, Mill as well), which can convert TypeScript definitions into idiomatic Scala.js code.
The conversion can be done on the fly, the dependencies are imported directly from NPM, you can publish generated code as a regular Scala.js library, it can minimise and compile the generated code for you... just excellent.
I won't go through setting the plugin up, because it's quite easy and there are already examples on the website.
One important aspect of this plugin is by default the definitions that it generates are local to your machine - there's no registry where they're published, if you want that - it's up to you to set it up.
Using pre-generated artifacts
So I took a long and hard look at the documentation (I know, right?) on how to publish the generated code as a library, and decided to publish the artifact to Maven Central.
Here's the library itself and it can be added to our SBT project by just including this line:
libraryDependencies +=
"com.indoorvivants.cloudflare" %%% "worker-types" % "3.3.0"
Writing Cloudflare Functions in Scala
After adding the pre-published types to our build, here's what it looks like:
// ./build.sbt
name := "cloudflare-test"
scalaVersion := "3.1.1"
enablePlugins(ScalaJSPlugin)
scalaJSLinkerConfig ~= { conf =>
conf
.withModuleKind(ModuleKind.ESModule)
}
libraryDependencies +=
"com.indoorvivants.cloudflare" %%% "worker-types" % "3.3.0"
And this means we can now rewrite our Scala code to use the types provided by the library. So let's take this opportunity and put a little more meat on the bones of those two sample functions:
package app
import com.indoorvivants.cloudflare.cloudflareWorkersTypes.*
import com.indoorvivants.cloudflare.std
import scala.scalajs.js.annotation.JSExportTopLevel
type Params = std.Record[String, scala.Any]
@JSExportTopLevel(name = "onRequest", moduleID = "request_headers")
def request_headers(context: EventContext[Any, String, Params]) =
val str = StringBuilder()
context.request.headers.forEach { (_, value, key, _) =>
str.append(s"Keys: $key, value: $value\n")
}
global.Response("hello, world. Your request comes with \n" + str.result)
@JSExportTopLevel(name = "onRequestGet", moduleID = "request_method")
def request_method(context: EventContext[Any, String, Params]) =
global.Response("Your request came via " + context.request.method)
The request_method function simple outputs the HTTP verb used for the request (which in this case will always be GET, take a closer look to see why).
The request_headers function outputs the values for all the headers of the request.
Now that we have local environment, we can check that it works locally:
❯ curl http://127.0.0.1:8788/request_method
Your request came via GET%
❯ curl http://127.0.0.1:8788/request_headers -H hello:blog
hello, world. Your request comes with
Keys: accept, value: */*
Keys: cf-connecting-ip, value: 127.0.0.1
Keys: cf-ipcountry, value: GB
Keys: cf-ray, value: 3ff76e8bd03328c8
Keys: cf-visitor, value: {"scheme":"https"}
Keys: hello, value: blog
Keys: host, value: 127.0.0.1:8788
Keys: user-agent, value: curl/7.77.0
Keys: x-forwarded-proto, value: https
Keys: x-real-ip, value: 127.0.0.1
Excellent! After we commit and push, we can see the same changes deployed:
❯ curl https://cloudflare-functions-scalajs.pages.dev/request_method
Your request came via GET%
❯ curl https://cloudflare-functions-scalajs.pages.dev/request_headers -H test:hello
hello, world. Your request comes with
Keys: accept, value: */*
Keys: accept-encoding, value: gzip
Keys: cf-connecting-ip, value: <get-away-haxxors>
Keys: cf-ipcountry, value: GB
Keys: cf-ray, value: 6d3d37ef8cef76a1
Keys: cf-visitor, value: {"scheme":"https"}
Keys: connection, value: Keep-Alive
Keys: host, value: cloudflare-functions-scalajs.pages.dev
Keys: test, value: hello
Keys: user-agent, value: curl/7.77.0
Keys: x-forwarded-proto, value: https
Keys: x-real-ip, value: <get-away-haxxors>
Deploying Scala functions to Cloudflare
As mentioned above, the Cloudflare Pages deploy process is pull-based, meaning each push to a branch will trigger a build on Cloudflare's own infrastructure.
This means that we have to use the limited tools available to us during build process.
The good news is that the build environment has (among other things) Java 8 installed
Having a JVM is all we need to bootstrap SBT and build our JavaScript output.
Additionally, we can configure the build to run any build command - in our case
we will configure it to run a ./deploy.sh - a shell script we're yet to write
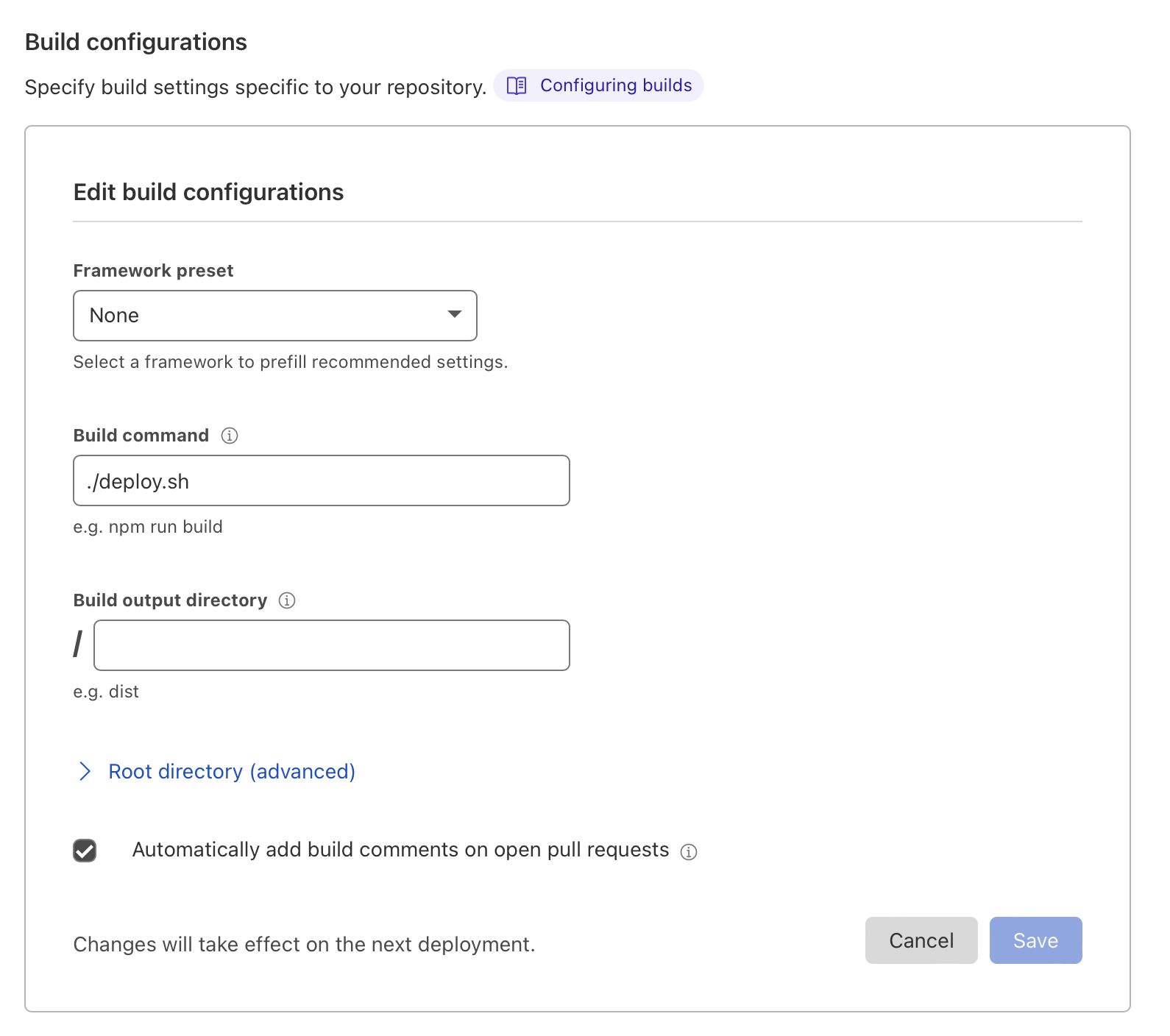
The script itself is very simple:
#!/bin/sh
# 1
curl -Lo sbt https://raw.githubusercontent.com/sbt/sbt/v1.6.1/sbt
# 2
chmod +x ./sbt
# 3
./sbt fullLinkJS
# 4
cp -r target/scala-3*/cloudflare-test-opt/ ./functions
- Download SBT's standalone launcher
- Make the launcher executable
- Invoke
fullLinkJSsbt command, to produce JavaScript files - Copy the output into a top-level
./functionsfolder
And that's it! We can now remove the ./functions folder from our repo, and push the
new version with this deploy script.
The logs will indeed confirm that our deploy script is run correctly:
11:52:36.822 Executing user command: ./deploy.sh
11:52:36.828 % Total % Received % Xferd Average Speed Time Time Time Current
11:52:36.829 Dload Upload Total Spent Left Speed
11:52:36.999
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 27878 100 27878 0 0 159k 0 --:--:-- --:--:-- --:--:-- 160k
11:52:37.152 downloading sbt launcher 1.6.1
11:52:37.911 [info] [launcher] getting org.scala-sbt sbt 1.6.1 (this may take some time)...
11:52:41.288 [info] [launcher] getting Scala 2.12.15 (for sbt)...
11:52:43.112 [info] welcome to sbt 1.6.1 (Private Build Java 1.8.0_252)
11:52:45.783 [info] loading settings for project repo-build from plugins.sbt ...
11:52:46.617 [info] loading project definition from /opt/buildhome/repo/project
11:52:51.056 [info] loading settings for project repo from build.sbt ...
11:52:51.275 [info] set current project to cloudflare-test (in build file:/opt/buildhome/repo/)
11:52:53.337 [info] compiling 1 Scala source to /opt/buildhome/repo/target/scala-3.1.1/classes ...
11:52:57.168 [info] done compiling
11:52:57.917 [info] Full optimizing /opt/buildhome/repo/target/scala-3.1.1/cloudflare-test-opt
11:52:59.563 [success] Total time: 8 s, completed Feb 11, 2022 10:52:59 AM
11:52:59.943 Finished
11:53:00.461 ▲ [WARNING] Top-level "this" will be replaced with undefined since this file is an ECMAScript module
11:53:00.461
11:53:00.461 ../../../buildhome/repo/functions/internal-0e1e8a7b68809aecf0131c695a7a6be34fa430dd.js:7:19:
11:53:00.461 7 │ "fileLevelThis": this
11:53:00.461 │ ~~~~
11:53:00.461 ╵ undefined
11:53:00.461
11:53:00.461 This file is considered an ECMAScript module because of the "export" keyword here:
11:53:00.461
11:53:00.461 ../../../buildhome/repo/functions/internal-0e1e8a7b68809aecf0131c695a7a6be34fa430dd.js:5449:0:
11:53:00.461 5449 │ export { $d_scm_StringBuilder as $d_scm_StringBuilder };
11:53:00.461 ╵ ~~~~~~
11:53:00.461
11:53:00.474 1 warning(s) when compiling Worker.
11:53:00.487 Validating asset output directory
11:53:02.063 Deploying your site to Cloudflare's global network...
11:53:21.939 Success: Your site was deployed!
Improving our development setup
Current we don't have anything that makes our life easier when moving Scala.js output to the ./functions folder
recognised by Wrangler.
We can improve on that by adding a new task to our SBT build:
lazy val buildWorkers = taskKey[Unit]("Copy Scala.js output to the ./function folder")
buildWorkers := {
// where Scala.js puts the generated .js files
val output = (Compile / fastLinkJS / scalaJSLinkerOutputDirectory).value
// trigger (if necessary) JS compilation
val _ = (Compile / fastLinkJS).value
// where (relative to root of our build) we want to copy them
val destination = (ThisBuild / baseDirectory).value / "functions"
// access SBT's logger, for ease of debugging
val log = streams.value.log
// .js files produced by Scala.js
val filesToCopy = IO.listFiles(output).filter(_.ext == "js")
if(destination.exists()) {
// .js files already at the destination
val filesToDelete = IO.listFiles(destination).filter(_.ext == "js")
// delete stale .js files
filesToDelete.foreach {f =>
log.debug(s"Deleting $f")
}
}
// copy new .js files to destination
filesToCopy.foreach {from =>
val to = destination / from.name
log.debug(s"Copying $from to $to")
IO.copyFile(from, to)
}
}
Now if we run sbt ~buildWorkers at the root of our project, changes to Scala files will be picked up automatically,
and new JS files will be produced and copied to ./functions.
And changes in ./functions folder will be picked up by Wrangler, recompiled and redeployed to our local setup.
We now have what's called on Twitter a ✨ developer workflow ✨.
# in one terminal
$ sbt ~buildWorkers
# in another terminal
$ wrangler pages dev .
Building an app
We now have the minimal set of features and processes explained and put in place to develop something more complex.
As a sample application, we will develop a tool to allow for anonymous ranking of prominent hot takes. Hot takes are nuanced enough to replace people's entire personalities, so there's plenty of complexity do demonstrate app's key features.
Here's the mockup of the interface I'd like:
┌───────────────────────────────────────────────────────┐
│ │
│ │
│ +-+-+-+ +-+-+-+-+-+ +-+-+-+-+-+-+ │
│ |H|o|t| |t|a|k|e|s| |g|a|l|o|r|e| │
│ +-+-+-+ +-+-+-+-+-+ +-+-+-+-+-+-+ │
│ │
│ │
│ ┌─────────────────────────────────────────────┐ │
│┌──────┤ ┌────┐ ┌────┐ │ │
││ 150 │PRs bad, trust good │Yah │ │Nah │ │ │
│└──────┤ └────┘ └────┘ │ │
│ └─────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│┌──────┤ ┌────┐ ┌────┐ │ │
││ -12 │Capitalism bad, communism good │Yah │ │Nah │ │ │
│└──────┤ └────┘ └────┘ │ │
│ └─────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────┐ │
│┌──────┤ ┌────┐ ┌────┐ │ │
││ 256 │crypto bad, bank good │Yah │ │Nah │ │ │
│└──────┤ └────┘ └────┘ │ │
│ └─────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘
And here are the requirements:
-
Hot takes must be stored in the database
-
People can vote Up or Down (each statement is either wrong or right, there can't be anything in between)
-
Whenever someone votes for a particular hot take, they shouldn't be able to vote for it for 24 hours - a cool down period to come to one's senses and do a 180.
Before we outline the API and address frontend concerns, let's take a closer look at requirement #1 - where the hell are we going to get a "database" whatever that is?
Persistence on Cloudflare Workers
Generally, we have the following two options:
Using an external database
These days there's an abundance of managed databases, some of those being part of other cloud provider's offerings (Amazon RDS & DynamoDB, Google's Firebase, etc.), and some of those being standalone database-only offerings.
Cloudflare both has database partners and official examples of how to call and setup things like AWS DynamodDB and RDS.
Using Cloudflare-provided storage
For some usecases, Cloudflare's own offerings might be enough.
One of those is Workers KV - a low-latency key-value data store, optimised for read-heavy workflows. It has a very simple storage model, uses last-write-wins conflict resolution strategy, and lacks atomic operations (such as atomic increment/decrement) and conditional queries.
Another is Durable Objects which has transactional APIs and acts as a JavaScript object, allowing for a richer data structure.
While Workers KV looks unsuitable for our usecase (we need atomic increments), its simplicity is attractive for an app that realistically won't receive any meaningful traffic. I also completely misunderstood Durable Objects during prep work for this post, but it's not as good of a justification.
Working with KV
The API for KV is defined as KVNamespace in the TypeScript definitions, and
translated to Scala the main 3 methods we will be interested in are:
type Key = String
type Value = String
def get(key: Key): Promise[Value | Null]
def put(key: Key, value: Value): Promise[Unit]
def list(): Promise[List[Key]]
(we will harden this API later)
What we need to figure out is how to get a hold of an instance of KVNamespace
to invoke these methods.
The way it's done in Cloudflare Functions is quite simple - you can bind a namespace to a global variable that will be made available by the runtime.
Let's create and configure the namespace first.
Configuring namespace
Go to Workers > KV > Create namespace section of the Cloudflare dashboard
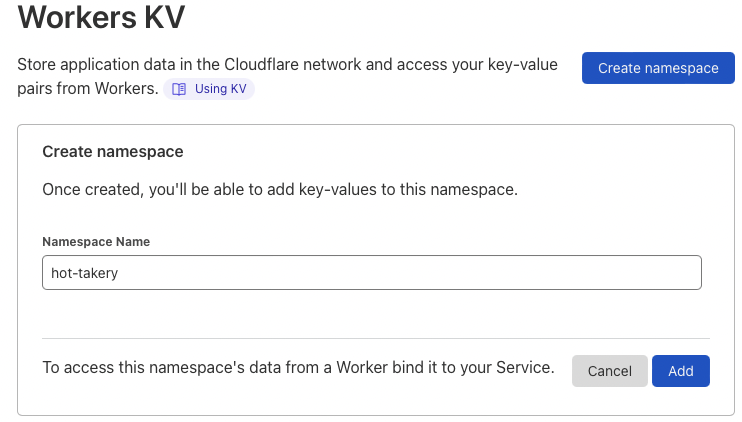
Now we need to make our project's functions aware of this KV namespace
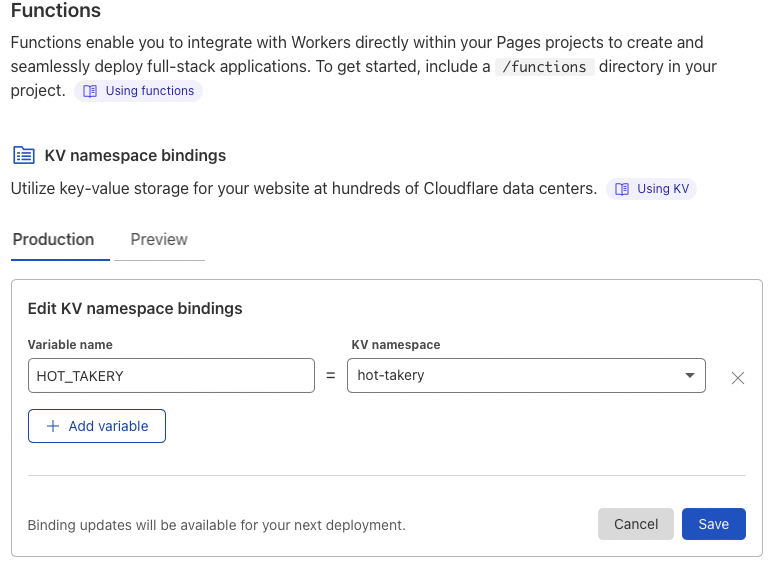
With this configuration, we now have a dedicated namespace and a way to reference it - by name in the global scope of the function's runtime.
Additionally, we can create a separate namespace (say, hot-takery-preview) and bind it in Preview configuration - this way environments created from PRs and branches
will use a separate database.
Accessing KV namespace
If you recall, our function signatures looked like this:
@JSExportTopLevel(name = "onRequestGet", moduleID = "request_method")
def request_method(context: EventContext[Any, String, Params]) =
...
Turns out, to get access to the global variables, we can simply convert the
first type parameter in EventContext into a scala.scalajs.js.Dynamic:
import scala.scalajs.js.{Dynamic => JSDynamic}
@JSExportTopLevel(name = "onRequestGet", moduleID = "test_db")
def test_db(context: EventContext[JSDynamic, String, Params]) =
// 1 // 2
val res = context.env.HOT_TAKERY.asInstanceOf[KVNamespace]
// 3 // 4
res.list().`then`(results => global.Response(results.keys.length.toString))
-
We access the
envparameter of EventContext and dynamically retrieve a variable namedHOT_TAKERY- Scala.js will correctly translate -
Retrieved value is cast to
KVNamespace- which comes from our generated bindings -
We invoke
list()method to get the list of all keys available -
We create a response with the number of retrieved keys
To test this locally, we need to tell Wrangler to create a dummy database for us and bind it to correct variable name:
$ wrangler pages dev . --kv=HOT_TAKERY
To make sure our database is usable, let's modify the test_db function to
manage some sort of counter:
@JSExportTopLevel(name = "onRequestGet", moduleID = "test_db")
def test_db(context: EventContext[JSDynamic, String, Params]) =
val database = context.env.HOT_TAKERY.asInstanceOf[KVNamespace]
def getCurrent: Promise[Int] =
database.get("test-counter").`then`{
case null => 0
case str => str.toInt
}
def put(value: Int): Promise[Unit] =
database.put("test-counter", value.toString)
getCurrent.`then`(num =>
put(num + 1).`then`(_ =>
global.Response(s"Current value is $num")
)
)
Note that we have to use backticks around then because it's a keyword in Scala 3,
and we need to use it when working with JS' Promises. We'll make it better in a second.
We can test that it works locally:
$ curl http://localhost:8788/test_db
Current value is 7
$ curl http://localhost:8788/test_db
Current value is 8
And after we push, it works on our deployment:
❯ curl https://cloudflare-functions-scalajs.pages.dev/test_db
Current value is 3
❯ curl https://cloudflare-functions-scalajs.pages.dev/test_db
Current value is 4
Making Promise nicer to work with
While I understand the nature of then in principle, I'm more accustomed
to the map and flatMap used with things like Future and Cats Effect IO.
So let's add a couple of extension methods:
import scala.util.NotGiven
import scala.annotation.implicitNotFound
extension [A](p: Promise[A])
inline def map[B](inline f: A => B)(using
@implicitNotFound("Seems like you need `flatMap` instead of `map`")
ev: NotGiven[B <:< Promise[?]]
): Promise[B] =
p.`then`(f)
inline def flatMap[B](inline f: A => Promise[B]): Promise[B] =
p.`then`(f)
inline def withFilter(inline pred: A => Boolean): Promise[A] =
flatMap { a =>
if pred(a) then Promise.resolve(a)
else Promise.reject(MatchError(a))
}
inline def *>[B](other: Promise[B]): Promise[B] =
flatMap(_ => other)
end extension
This defines map and flatMap, and additionally makes map a little bit
safer by preventing the passed function from returning Promise.
Making the KV interface safer
While we confirmed that the generated interface is usable, I'd like to reduce it a little bit for safety purposes.
First of all, let's use opaque types to reduce the usage of naked Strings for
both keys and values
// we will use this to define String-like opaque types
trait OpaqueString[T](using ap: T =:= String):
def apply(s: String): T = ap.flip(s)
extension (k: T)
def raw = ap(k)
def into[X](other: OpaqueString[X]): X = other.apply(raw)
object KV:
opaque type Key = String
object Key extends OpaqueString[Key]
opaque type Value = String
object Value extends OpaqueString[Value]
end KV
I've put them into a KV object which is in fact a companion to what
will become a reduced interface for KVNamespace.
Because we have a single KV namespace to store hot takes, vote counters, and IP blocks, we will use prefixes to differentiate between those different types of data.
trait KV[T](scope: String)(using ap: T =:= KVNamespace):
def apply(kv: KVNamespace): T = ap.flip(kv)
extension (kv: T)
def descope(key: KV.Key): KV.Key =
if key.raw.startsWith(scope) then KV.Key(key.raw.drop(scope.length))
else key
def get(key: KV.Key): Promise[Option[KV.Value]] =
ap(kv)
.get(scope + key.raw)
.map(str => Option(str))
.map(_.map(KV.Value.apply))
def put(key: KV.Key, value: KV.Value): Promise[Unit] =
ap(kv).put(scope + key.raw, value.raw)
def putWithExpiration(
key: KV.Key,
value: KV.Value,
expiresIn: FiniteDuration
): Promise[Unit] =
ap(kv).put(
scope + key.raw,
value.raw,
KVNamespacePutOptions().setExpirationTtl(expiresIn.toSeconds.toInt)
)
def list(): Promise[List[KV.Key]] =
ap(kv)
.list(KVNamespaceListOptions.apply().setPrefix(scope))
.map(result => result.keys.map(k => descope(KV.Key(k.name))).toList)
end extension
end KV
Now we can define our "views" of the database by using opaque types:
object DB:
opaque type HotTakes = KVNamespace
object HotTakes extends KV[HotTakes]("hot-take-")
opaque type Votes = KVNamespace
object Votes extends KV[Votes]("votes-")
opaque type IPBlocks = KVNamespace
object IPBlocks extends KV[IPBlocks]("block-")
end DB
Note that same effect could've been achieved with classes and composition, I just wanted an excuse to use opaque types.
With those definitions, we can start implementing our simple logic.
App implementation
Defining domain
Our domain is actually quite small, so let's define a few main types:
object Domain:
opaque type IP = String
object IP extends OpaqueString[IP]
opaque type HotTakeID = String
object HotTakeID extends OpaqueString[HotTakeID]
opaque type HotTakeInfo = String
object HotTakeInfo extends OpaqueString[HotTakeInfo]
case class HotTake(id: HotTakeID, info: HotTakeInfo, votes: Int)
case class VoteAction(hotTake: HotTakeID, vote: Vote)
enum Vote:
case Yah, Nah
end Domain
Extracting IP from a request
User's IP address will be placed by Cloudflare into a cf-connecting-ip header,
and we can use x-real-ip as (probably unnecessary) fallback:
def getIP(headers: Headers): Promise[IP] =
val ipSource =
Option(headers.get("cf-connecting-ip")) orElse
Option(headers.get("x-real-ip"))
ipSource match
case None => Promise.reject("Missing X-Real-IP header!")
case Some(s) => Promise.resolve(IP(s))
end getIP
Blocking repeated voting
def blockVoting(ip: IP, hotTakeId: HotTakeID)(using
db: IPBlocks
): Promise[Unit] =
import scala.concurrent.duration.*
val key = KV.Key(ip.raw + "-" + hotTakeId.raw)
db.putWithExpiration(key, KV.Value(""), 24.hours)
def votingIsBlocked(ip: IP, hotTakeId: HotTakeID)(using
db: IPBlocks
): Promise[Boolean] =
val key = KV.Key(ip.raw + "-" + hotTakeId.raw)
db.get(key).map(_.isDefined)
Because KV natively supports object expiration, all we need to do is add a record with the correct key and expiration options.
Update votes counter
This is where lack of atomicity can lead to data corruption, but we don't really care.
def changeVote(hotTakeId: HotTakeID, vote: Vote)(using
db: Votes
): Promise[Unit] =
val key = hotTakeId.into(KV.Key)
for
current <- db.get(key)
intValue = current.flatMap(_.raw.toIntOption).getOrElse(0)
newValue = vote match
case Vote.Yah => intValue + 1
case Vote.Nah => intValue - 1
_ <- db.put(key, KV.Value(newValue.toString))
yield ()
end changeVote
Extracting vote data from a POST request
We will use good ol' HTML form submission for votes, and we need to extract some data from it:
def extractVote(fd: FormData): Promise[VoteAction] =
val hotTakeId: Option[HotTakeID] =
Option(fd.get("id"))
.collectFirst { case s: String =>
s
}
.map(HotTakeID.apply)
val vote: Option[Vote] = Option(fd.get("vote"))
.collectFirst { case s: String => s.trim.toLowerCase }
.collectFirst {
case "yah" => Vote.Yah
case "nah" => Vote.Nah
}
hotTakeId.zip(vote).map(VoteAction.apply) match
case None => Promise.reject("Form data is invalid")
case Some(o) => Promise.resolve(o)
end extractVote
Defining /vote API
With these small building blocks in place, we have enough to define the implementation of /vote endpoint:
def badRequest(msg: String): Promise[Response] =
Promise.resolve(global.Response(msg, ResponseInit().setStatus(400)))
@JSExportTopLevel(name = "onRequestPost", moduleID = "vote")
def vote(context: EventContext[JSDynamic, String, Params]) =
val database = context.env.HOT_TAKERY.asInstanceOf[KVNamespace]
given hotTakes: HotTakes = HotTakes(database)
given Votes = Votes(database)
given IPBlocks = IPBlocks(database)
val headers = context.request.headers
val redirectUri = global.URL(context.request.url).setPathname("/").toString
for
// processing input
formData <- context.request.formData()
ip <- getIP(headers)
case VoteAction(hotTakeId, vote) <- extractVote(formData)
hotTakeExists <- hotTakes.get(hotTakeId.into(KV.Key)).map(_.isDefined)
blocked <- votingIsBlocked(ip, hotTakeId)
result <-
if !hotTakeExists then badRequest("Hot take doesn't exist!")
else if blocked then
badRequest(
"You are temporarily blocked from voting for this hot take"
)
else
// block IP and change vote counter
blockVoting(ip, hotTakeId) *>
changeVote(hotTakeId, vote) *>
Promise.resolve(global.Response.redirect(redirectUri))
yield result
end for
end vote
Our endpoint can be tested using curl:
$ curl -XPOST http://localhost:8788/vote -d id=hello -d vote=yah
Hot take doesn't exist!
Unfortunately it will return 400 Bad Request for all input that is syntactically valid, and 500 for the rest.
We can't do better at this point because there are no more worlds to conquer hot takes in the database.
Retrieving hot takes
Let's put together a small function to retrieve hot take's text along with its voter count:
def getHotTake(
id: HotTakeID
)(using
hotTakes: HotTakes,
votes: Votes
): Promise[Option[HotTake]] =
for
retrieved <- hotTakes.get(id.into(KV.Key))
retrievedCount <- votes.get(id.into(KV.Key))
info = retrieved.map(_.into(HotTakeInfo))
count = retrievedCount.flatMap(_.raw.toIntOption) orElse Option(0)
yield (info zip count).map { case (i, cnt) => HotTake(id, i, cnt) }
With this function, we can implement a general function to list all hot takes and their counts present in the database.
def listHotTakes(using
hotTakes: HotTakes,
votes: Votes
): Promise[List[HotTake]] =
hotTakes.list().flatMap { keys =>
val ids = keys.map(_.into(HotTakeID)).map(getHotTake)
Promise.all(scalajs.js.Array.apply(ids*)).map(_.toList.flatten)
}
Rendering HTML pages
We could, of course, write HTML by hand like any reasonable person would. But we won't. We didn't make it this far in search of "reasonable".
Let's add ScalaTags as a dependency to our build.sbt:
libraryDependencies += "com.lihaoyi" %%% "scalatags" % "0.11.1"
And start defining building blocks for our HTML page. We will of course use Bootstrap to deceive ourselves into thinking we can produce a usable interface.
First thing is rendering individual hot take's card:
def renderHotTake(take: HotTake) =
import scalatags.Text.all.*
div(
cls := "card",
div(
cls := "card-body",
div(
cls := "row",
div(cls := "col-2", style := "text-align: center", h1(take.votes)),
div(cls := "col-6", cls := "align-middle", h2(cls := "card-title", take.info.raw)),
div(
cls := "col-3",
form(
action := "/vote",
method := "POST",
input(`type` := "hidden", name := "id", value := take.id.raw),
input(
`type` := "submit",
value := "yah",
name := "vote",
cls := "btn btn-success"
),
input(
`type` := "submit",
value := "nah",
name := "vote",
cls := "btn btn-danger"
)
)
)
)
)
)
end renderHotTake
Which, with added Bootstrap magic, will render each hot take as a card like this:

This function can be called from the main page:
def renderHotTakes(takes: List[HotTake]) =
import scalatags.Text.all.*
html(
head(
scalatags.Text.tags2.title("Reviews"),
link(
href := "https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css",
rel := "stylesheet"
)
),
body(
div(
cls := "container",
style := "padding:20px;",
h1("Hot takes galore"),
takes.map(renderHotTake)
)
)
)
end renderHotTakes
Which renders the full page, worthy of an Oscar for special effects:
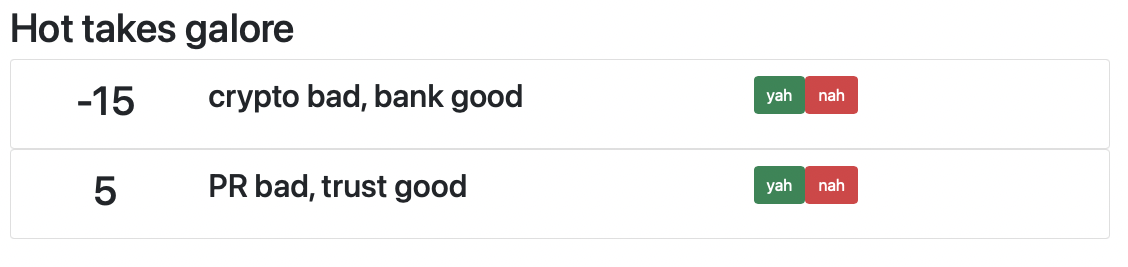
Now all we need to do is to define a function that will render the main page:
@JSExportTopLevel(name = "onRequestGet", moduleID = "index")
def index(context: EventContext[JSDynamic, String, Params]) =
val database = context.env.HOT_TAKERY.asInstanceOf[KVNamespace]
given HotTakes = HotTakes(database)
given Votes = Votes(database)
val htmlHeaders =
ResponseInit().setHeadersVarargs(
scala.scalajs.js.Tuple2("Content-type", "text/html")
)
listHotTakes.map { takes =>
global.Response(renderHotTakes(takes).render, htmlHeaders)
}
end index
Nothing special, we just delegate to things we have already defined.
Conclusion
And this is it!
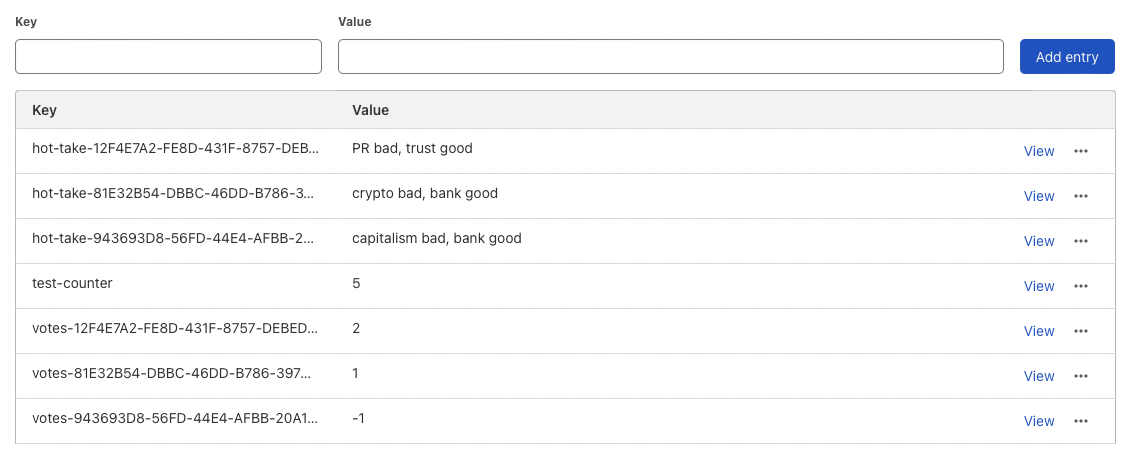
We can manually populate the deployed database:
And vote to our heart's content at publicly deployed page
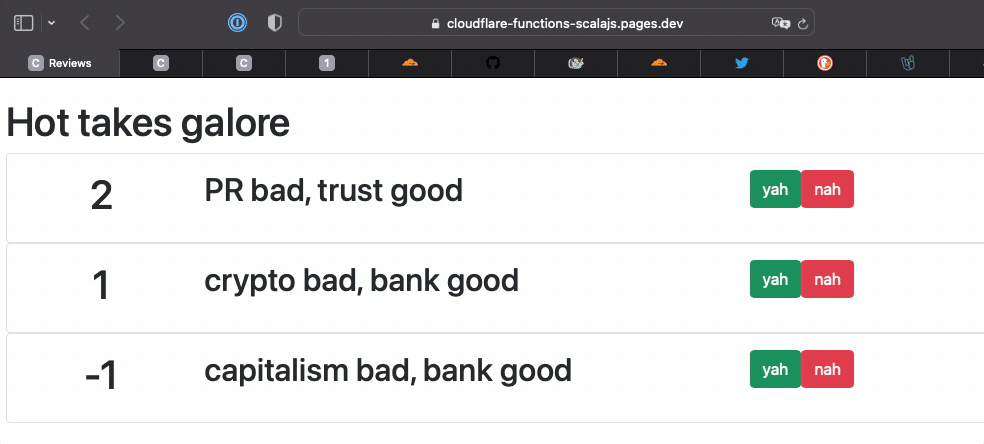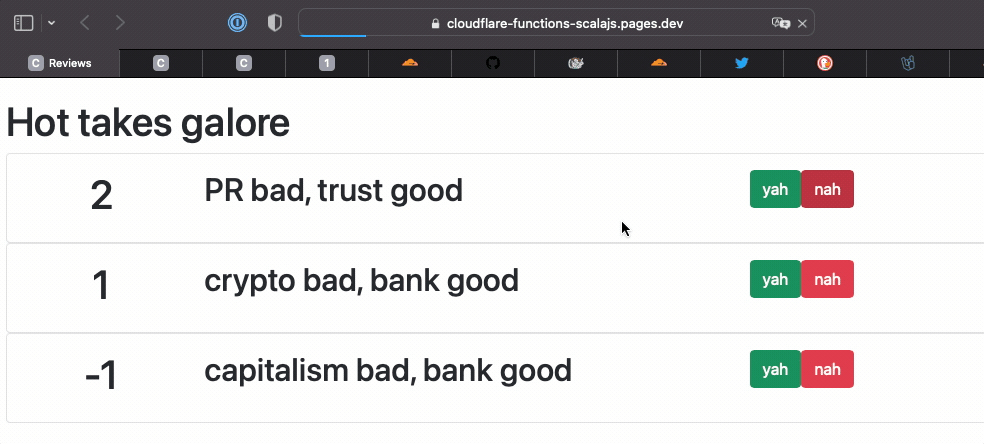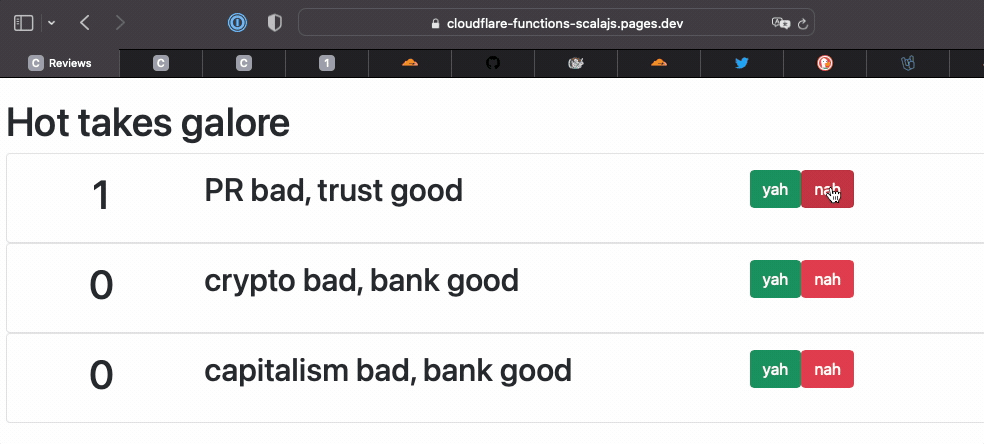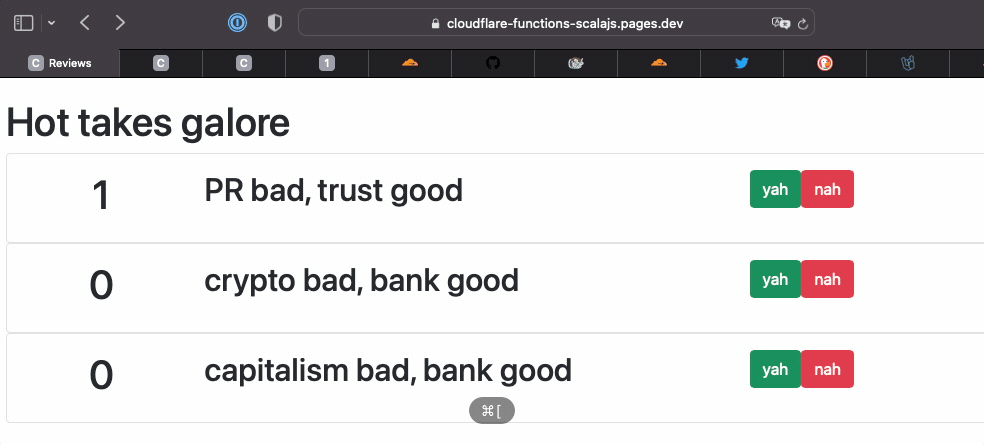
Overall, once I put the very minimal build steps in place, I found the experience quite joyful.
My main concern is lack of logging in case of failure - for example in the first version of the app I was validating IP addresses, and the fact that cloudflare uses IPv6 by default threw off my logic. This led me to chase all possible issues in the app, and then abandoning it completely because IPv6 format is batshit crazy